Introduction
These days, the words “genomics”, “genomic revolution” and “genomic data” are on everyone’s lips. Why is that? Why genomics and why now? What are the challenges of analysing genomic data?
In the last few decades, sequencing technologies have evolved incredibly fast, which led to a drop in the cost of sequencing a genome. In 2003, as part of the Human Genome Project, the first human genome sequenced costed billions of dollars and the individual and manual effort of many researchers. Today, we reached a point where sequencing a genome costs only $1K and only demands minimal human intervention. Soon, this will drop to $100.
The fast evolution in sequencing technology and the consequent drop in its cost translate into an unprecedented production of genomic data.
Not only is a massive amount of genomic data being produced, but this data is also extremely complex and we still do not fully understand the underlying biology and mechanisms. Hence, we are yet to see a set of standard go-to methods as these keep changing and evolving.
When someone, mostly bioinformaticians, try to make sense of genomic data, they usually follow a specific path to insights. This process is, in a lot cases, still very long and troublesome. At Lifebit, we identified some of its main challenges:
- Custom and inefficient solutions;
- Time wasted on computational tasks; and
- Limited pool of people who can actually produce these custom solutions for genomic data analysis.
What’s more, when an in-house solutions can be engineered, sooner or later on-premise resources will become the bottleneck and computation/storage needs to be moved to the cloud. However, using cloud comes with three main concerns: technically challenging, security and costs.
At Lifebit we created a platform-as-a-service, called CloudOS, which guides the user from data to insights and fully integrates with the way scientists already work. It advances their work through resource-management handling, cost optimisation and learning from previous analyses – all this wrapped around an intuitive UX/UI.

Why and how we are using Grakn
After such a long introduction, let us move on to the reason why we started this post: Why and how are we using Grakn to improve genomic analyses over cloud?
Let’s focus on where Grakn makes a difference for us: what is the best resource to run specific analyses over cloud? We needed a technology that would allow us to both efficiently store our data and easily use it to train an ML model.
At Lifebit, when it comes to picking (or delivering) a technology, we follow three basic rules:
- The onboarding needs to be fast and a user should be able to use the basic functionalities of the technology quickly.
- We care a lot about the technology’s learning curve: how long will it take a user to master the most complex functionalities?
- Evolvability: how stable and scalable is the technology over time as my needs evolve? In the case of a DB, we need it to not only model our data today but also be able to do so with an ever more complex and large dataset.
For us, the winner ended up being……GRAKN!! 🙂

Once we identified the right technology, we had to define what kind of data should be stored, and how it should be used to find the best resources to run an analysis.
When a user comes to CloudOS to perform genomic analyses over cloud, they first need to define which kind of workflow to use, then they picks the dataset to analyse and finally, on what kind of machine/resource they wants to run it on.
At Lifebit, we monitor real-time information of previous analyses, store it on Grakn and learn from them in order to provide suggestions to users on which instances are the most suitable for their analyses (depending on the nature of their workflows, data and needs).
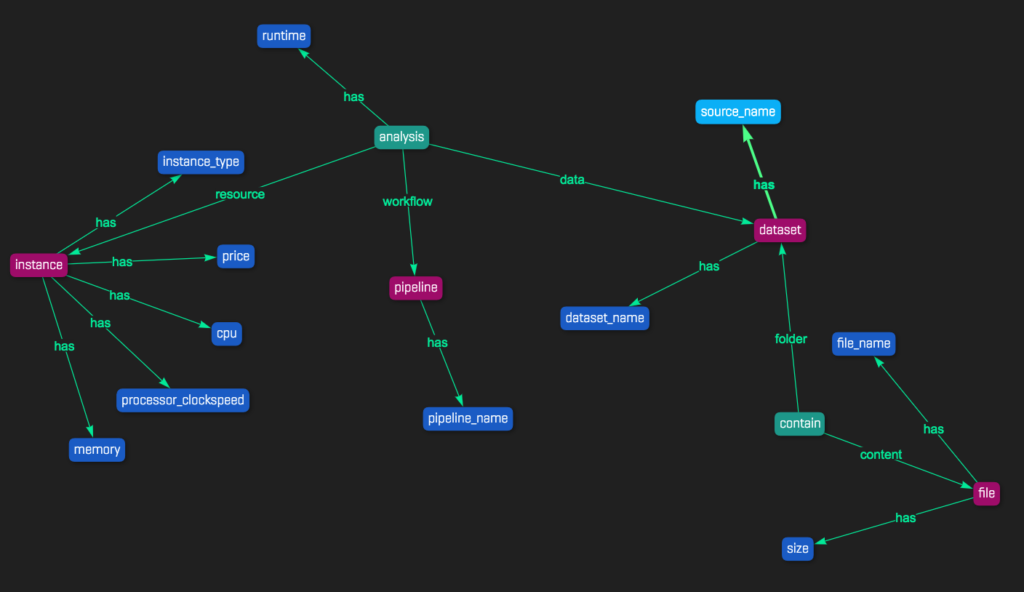
As mentioned above, the 3 main entities we use are: Pipeline, Dataset and Instance. Each has specific attributes; an instance, for example, can have a different number of CPUs, memory, storage, price, etc. These 3 main entities are connected through the analysis relationship – ie. running a specific pipeline, on a specific dataset, on a specific machine.
After storing this information, we need to learn from it. We trained a ML model in Python which could give us the answer we wanted.
In this case, Grakn was again very helpful since it provides a Python client. Here is a small example of how easy it can be:
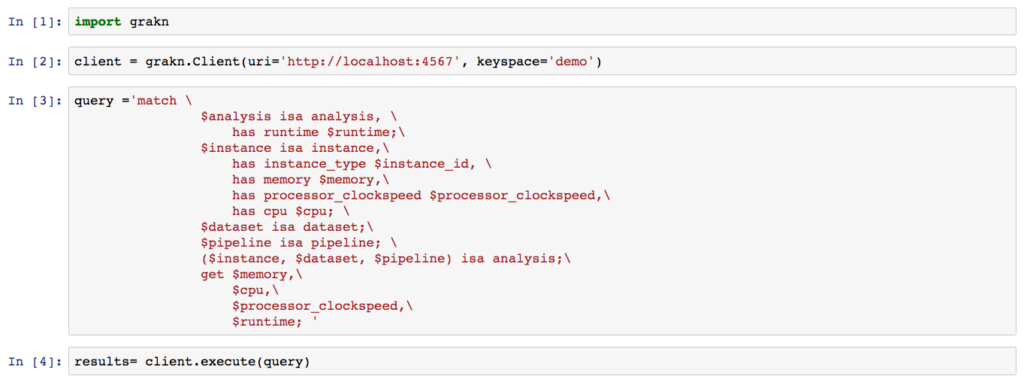
This is how we are using Grakn at Lifebit: to provide suggestions on resource optimisation to run genomics analyses over cloud while minimising costs and runtimes!
We would like to know what you think! Please fill out the following form or contact us at hello@lifebit.ai. We welcome your comments and suggestions!