
Targeting cancer through large-scale data analysis

Introduction to World Cancer Research Day
September 24th, World Cancer Research Day, is a global international movement dedicated to maintaining the momentum of cancer research. In 2020 alone, there were 18 million new cases of cancer recorded, with a striking 10 million new deaths worldwide.
While there has been tremendous progress in developing cancer therapies, it is only in the last ten years, which coincide with the sequencing of the human genome, that there has been a sharp uptake in targeted drugs. Furthermore, the road to drug approval is long, 10-15 years; in 2022, the US Federal Drug Administration listed 37 approvals for new drugs, with only 31% for cancer treatment.
Given this challenge, it is critical that the greater scientific community remain committed to cancer research and identifying innovative approaches to accelerate findings. Currently, the scientific community is failing – cancer drug discovery as it is (Drug Discovery 1.0) relies on wet lab approaches that take tens of years to complete, cost billions of dollars and patients are left without treatments. The solution to this problem is Drug Discovery 2.0 – harnessing the power of big data to bring life-saving therapies to people.
Furthermore, large-scale data analysis can help streamline the drug development pipeline by offering critical insights.
One promising approach to enhance cancer drug discovery is through large-scale data analysis, which leverages vast datasets to uncover new insights and expedite the research process.
Leveraging large-scale data analysis allows for a deeper understanding of patient responses to treatment.
This includes employing large-scale data analysis to ensure that therapies are tailored to individual needs.
Ultimately, large-scale data analysis empowers researchers to tackle the complexities of cancer treatment with confidence.
Utilizing large-scale data analysis can significantly enhance the accuracy and speed of cancer research outcomes.
This blog considers the challenges surrounding targeting cancer and how data, data federation, Trusted Research Environments, and end-to-end solutions are the solution to these problems.
The challenges surrounding targeting cancer
Cancer is fundamentally a problem of genetic dysregulation. In a healthy cell, some genes become active to promote cell growth and those that become active to stop cell growth. Both processes are essential within normal development. For example, cells need to grow to regenerate tissue if one falls and scrapes their knee, but there also are signals to stop cell growth if genetic abnormalities are detected.
As we advance, the role of large-scale data analysis in cancer research will only continue to grow in importance.
In cancer, the normal cellular signals to grow or not grow have gone awry. In genetic terms, identifying the root cause of a cancer can fall into two categories:
- Oncogenes: A gene capable of inducing characteristics of cancer cells. Cancers are often addicted to having these genes turned on.
- Tumour suppressor genes: A gene whose inactivation leads to tumour development.
Moreover, large-scale data analysis provides insights that can guide the development of innovative cancer therapies.
The utilization of large-scale data analysis in cancer research is paving the way for more personalized treatment strategies.
Researchers have done considerable work to identify how cancers sustain growth. In 2011, Professors Douglas Hanahan and Robert Weinberg published the foundational Hallmarks of Cancer, highlighting the key ways cancer cells continue to survive, which continue to be updated as new knowledge is gained.
To make the genetics even more complicated, 40% of cancer-causing genes are known to be transcription factors, or genes that control other genes. A stark example is the MITF gene in melanoma (a type of skin cancer)- turned on in the body long after its developmental role, this transcription factor plays a pro-survival role in melanoma.
Given this, there needs to be continued efforts and methods to uncover the complex genetics of cancer biology, and ultimately ways to discover targets and treat the disease.
Through large-scale data analysis, researchers can uncover hidden patterns within cancer genetics that guide future studies.
Drug Discovery 2.0: unravelling cancer’s complexities through big data
As mentioned above, with the sequencing of the human genome, there has been a sharp increase in targeted cancer therapies. The first generation of cancer drugs were designed to stop cell growth, which ultimately included both healthy and cancer cells, classifying these drugs as cytotoxic due to their many side effects.
However, as genomic sequencing data became available, researchers could begin to create molecular maps and identify cancer’s vulnerabilities. However, much of the work still took place in the lab, and Drug Discovery 1.0 was slow to progress.
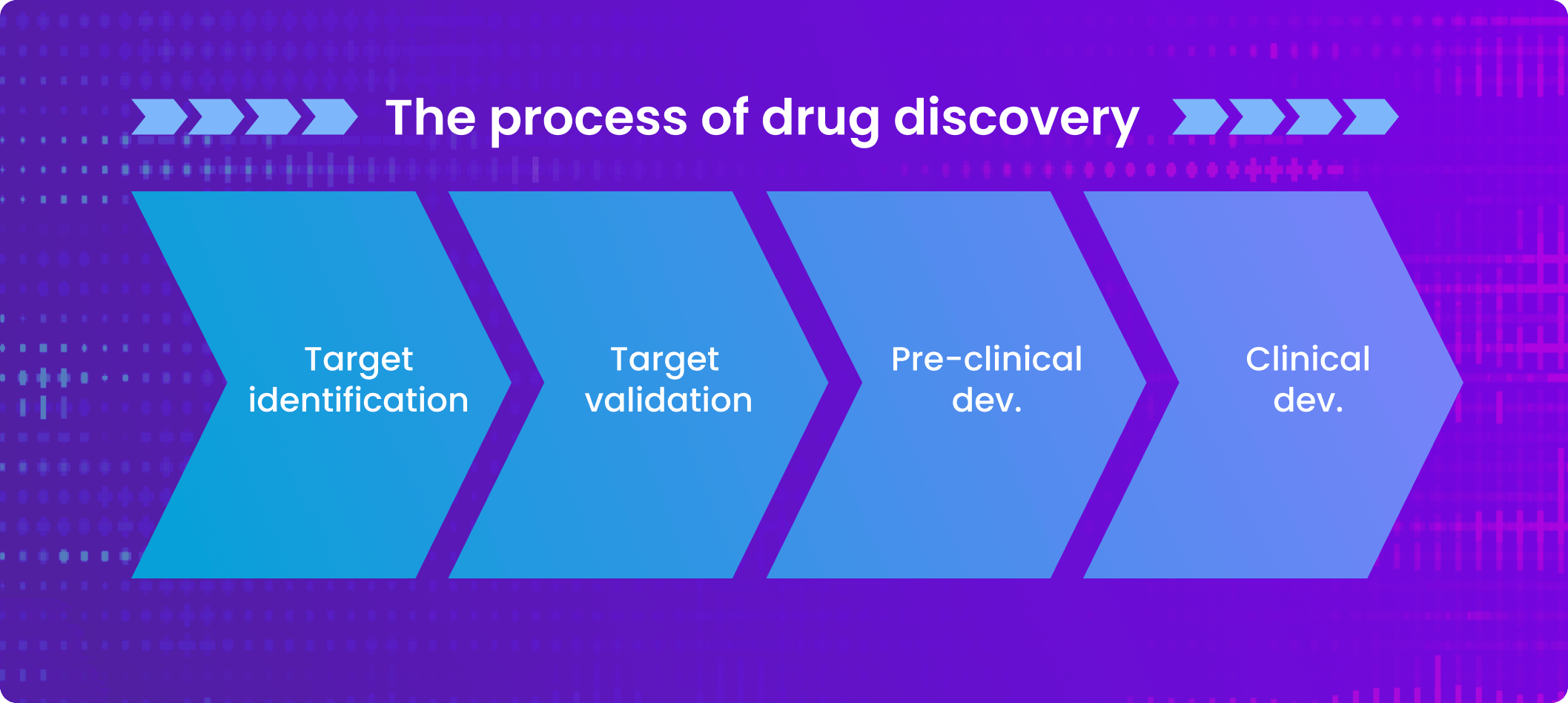
Drug Discovery 2.0 will revolutionise the speed at which we understand which genes may be turned on or off within a given cancer and the role that they are playing. One of the first stages in drug discovery is target identification, which refers to determining what a drug should attack in a specific disease context. Because Drug Discovery 2.0 uses computational approaches that examine the entire genome. Researchers can compare genomic data from healthy patients and those that have a specific cancer, streamlining how to identify what an effective drug should target. This approach has brought timelines of target identification from years down to months.
By leveraging large-scale data analysis, researchers are able to better understand the complexities of cancer biology.
Large-scale data analysis enables the identification of specific genetic targets that could be addressed with new therapies.
Consequently, large-scale data analysis is transforming how we approach oncology and treatment development.
Next in the process of drug discovery, a cancer target is experimentally validated and drugs are developed against it, allowing them to enter preclinical development. Large-scale data is essential in preclinical cancer research because it helps researchers understand if and how early-stage drugs are working, before they enter a patient.
In the realm of Drug Discovery 2.0, large-scale data analysis plays a crucial role in refining preclinical processes.
Once evaluated preclinically, cancer drugs will enter clinical development for testing in patients. Large-scale health data serves to understand how the drug is functioning in cancer patients and helps medical professionals identify the appropriate group to be treated with the drug. Drug Discovery 2.0 uses large-scale health data to group patients into disease subgroups, known as patient stratification, accelerating the translation of drugs into the clinic by maximising the likelihood of their success while preserving patient safety.
Considerations in using sensitive data within cancer research
Applying large-scale data analysis techniques has the potential to reduce the time it takes to bring new therapies to market.
Given the insights large sets of data can bring, it is unsurprising that there are now 2 to 40 billion gigabytes of data generated each year in cancer care and research and beyond. However, there are key considerations to ensuring that Drug Discovery 2.0 can achieve its full potential:
- Data needs to be accessible to researchers and clinicians without compromising patient security. Housing data in secure, Trusted Research Environments can maintain security while enabling research at scale.
- Employing federated technologies for secure access avoids copying and physically moving the data, allowing it to remain in with its jurisdictional boundaries.
- Linking and extracting insights from diverse data types across various sources and modalities (e.g. preclinical, clinical, molecular, imaging) enables researchers and clinicians to create a full biomedical picture for a given patient.
- End-to-End Analytical Solutions reduce the time to insights by keeping data access, standardisation and analysis all in one place.
- Implementing democratised, user-friendly, no-code solutions empower researchers regardless of a data science background.

Featured resource: Read our whitepaper on forecasting the future of genomic data management
Concluding remarks
Integrating large-scale data analysis into cancer research enhances collaboration across various disciplines.
Recognising World Cancer Day not only reminds us of the milestones that have been achieved but also invigorates momentum for cancer research to continue to improve patient outcomes. Secure access to usable health data, with the resources to derive insights, is the solution to accelerate these efforts and bring the scientific community into Drug Discovery 2.0 – a faster, smarter and more strategic approach to developing therapies. Lifebit is committed to doing our part to combat cancer through supporting and enabling large-scale research – ultimately striving for a healthier future for all.
About Lifebit
Lifebit provides health data standardisation services for clients, including Genomics England, Boehringer Ingelheim, Flatiron Health and more, to help researchers transform data into discoveries.
Moving forward, the integration of large-scale data analysis into clinical practices will be essential for improving treatment efficacy.