
Federated Trusted Research Environment (TRE)
Federated data at scale
A Trusted Research Environment (TRE) is a secure platform where researchers analyze sensitive data without it ever leaving its source — pioneered by Lifebit.










What is a Trusted Research Environment?
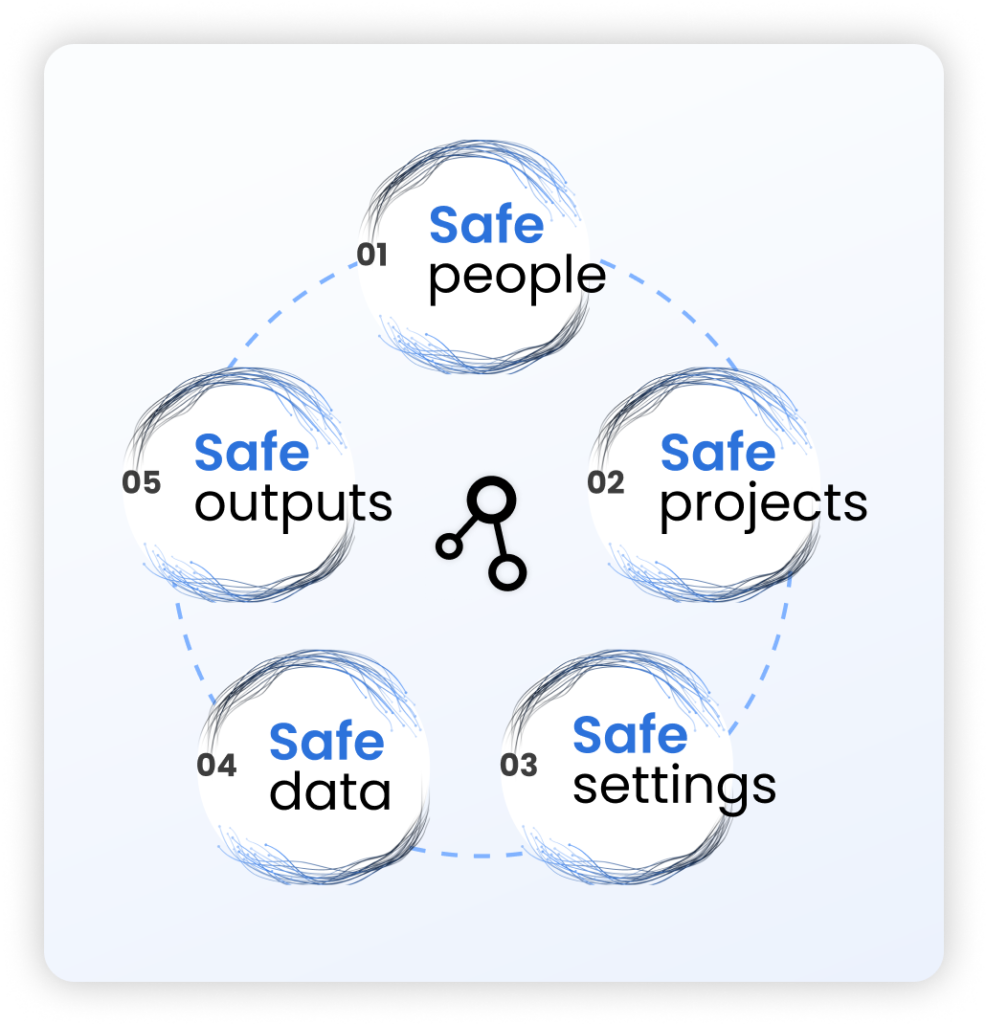
A Trusted Research Environment (TRE) is a secure, governed digital platform that gives approved researchers safe, remote access to sensitive health data — without the data ever leaving its source. Also known as “Data Safe Havens,” “Secure Data Environments” (SDEs), or “Safe Havens”, a Trusted Research Environment combines the Five Safes Framework with strict access controls and pseudonymization.
Lifebit’s federated Trusted Research Environment — first deployed in production at Genomics England — proves the model at national scale across biobanks, pharma, and government agencies.
A “TRE” is not a marketing label. Under the ONS Five Safes framework, data must stay at source, the environment must be controlled by the data controller, and every output must pass through an airlock review. If your platform copies data to a vendor cloud and allows raw downloads, it is a secure analysis platform — not a TRE.
Fast, specialized data harmonization & product creation
Lifebit is trusted by top pharma and data providers for creating data products at scale.
Most secure TRE, by federated design
From the pioneers of federation, Lifebit’s TRE uniquely brings analysis and computation to where biomedical data resides.
Only TRE to guarantee results
The only solution for fast, accurate results through a TRE that is proven to handle datasets from over 250M+ patients.
Why Lifebit?
The most widely adopted TRE on the market
Unmatched Usability and Security
in One Platform
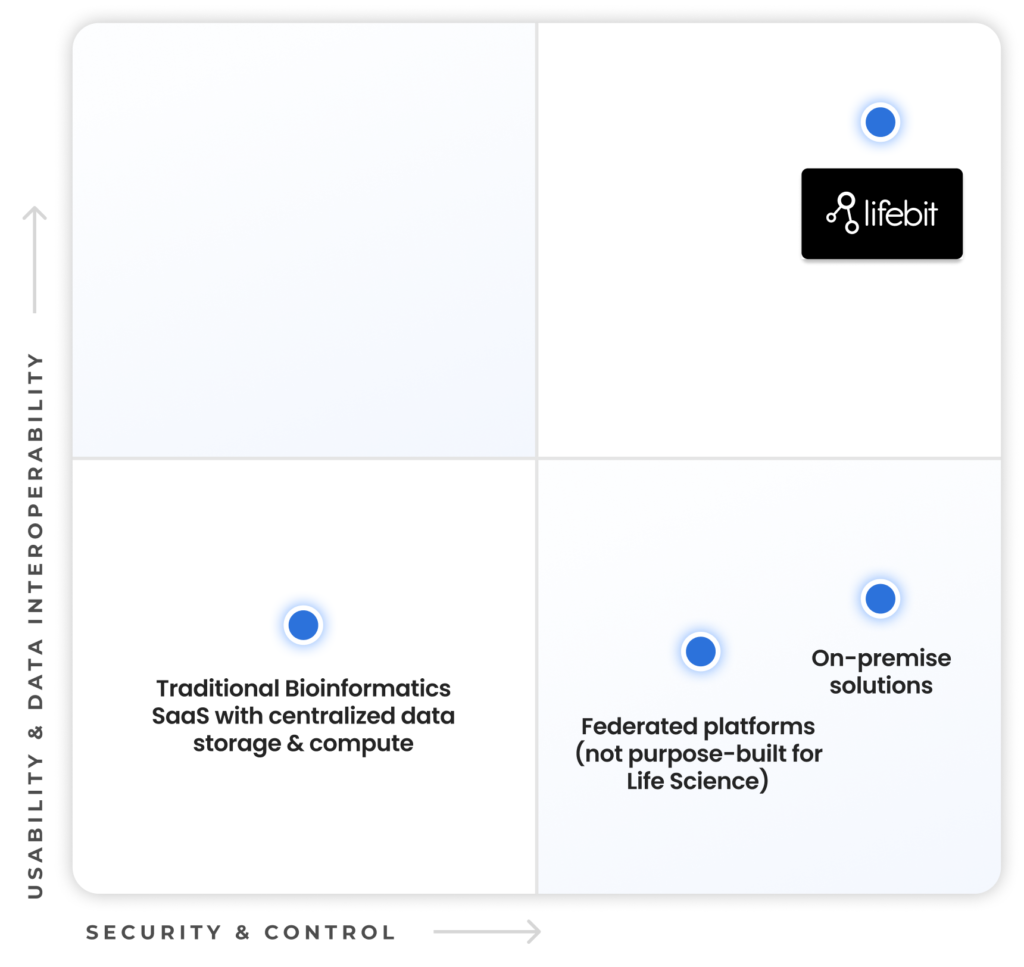
Achieving both security and usability for biomedical data is crucial to accelerate research and drive meaningful innovation.
Security & Control: Sensitive biomedical data must be stored securely with strictly controlled access to prevent data & privacy breaches. The traditional approach of anonymizing and transferring patient data to a central computing location leads to loss of data control and introduces re-identification risk. The only way to fully secure patient data is to keep data and computation in the organization’s jurisdiction and environment where it can be monitored, ensuring full compliance with data residency and privacy regulations.
Usability & Data interoperability: Biomedical data is often fragmented, unstructured, and challenging to use. Researchers need data products that are fit-for-purpose and ready for analysis, along with a platform that enables joint queries across distributed databases, supporting collaborative research without unnecessary barriers.
Lifebit’s Trusted Research Environment (TRE) stands alone as the only federated data platform purpose-built for life sciences and biomedical data, combining complete usability and data integration with uncompromising security and control.
Impact
Safeguard your sensitive biomedical data with Lifebit’s Trusted Research Environment
MOVE FASTER
5x
Faster than other solutions to identify data, create cohorts, deploy pipelines and AI models & perform analyses.
GET GUARANTEED RESULTS
100%
of our clients get results. Lifebit’s Platform is the only TRE to contractually guarantee results.
OVERCOME COMPLIANCE OBSTACLES
100%
Data stays in your environment, ensuring data security compliance and reducing risk.
How it works
1. Create Workspaces and invite users
Create Workspaces and invite users Lifebit’s TRE enables data admins to set up and manage Organizations and Workspaces in under 10 minutes, automatically connecting to your cloud and network with top-tier security configurations. Designed and tailored for seamless collaboration, the TRE offers self-service capabilities with customizable settings, role-based access control, integrated communication tools, and scalable solutions, ensuring every team member has the right access and resources.

2. Enable approved data in the Workspace
Data admins in a self-serve, seamless and efficient way connect relevant structured and unstructured data sources to the designated Workspace, ensuring that each research team has access to the exact data they need. Lifebit’s TRE, makes this process fully-self-serve, streamlined and secure for the first time.

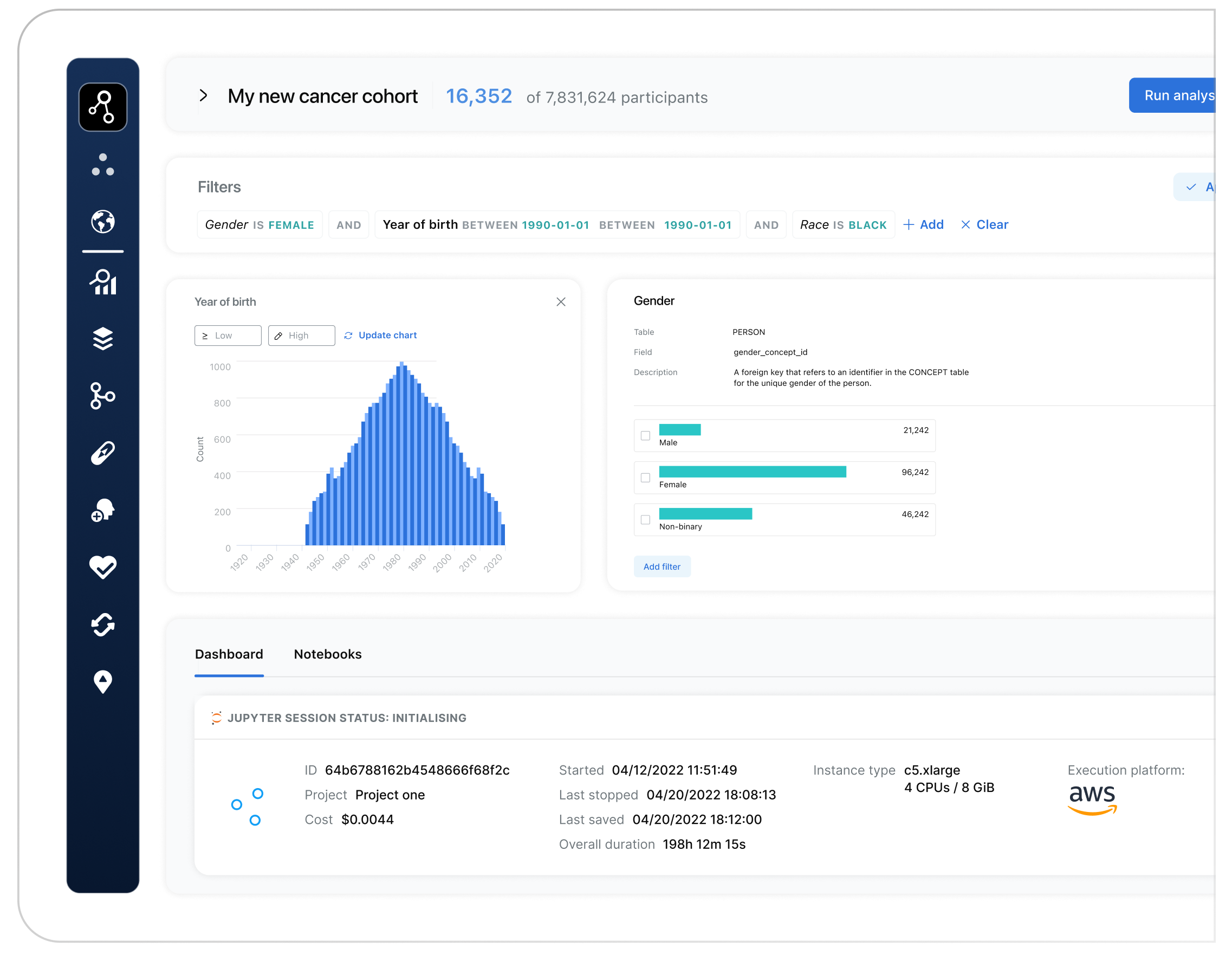
3. Access Workspace & create cohorts in 30 seconds
Effortlessly build precise cohorts of participants in a couple of clicks and as little as 30 seconds with Lifebit’s intuitive interface. Easily select participants by specific phenotypes and genotypes for highly targeted analysis. Lifebit’s TRE streamlines cohort creation, making it the fastest and most user-friendly solution for accurate, data-driven research.

4. Perform FAIR analysis to get results
- Perform biomarker discovery and complex analyses like GWAS, VEP, and PRS in 1-click without technical expertise
- Bring in your own tools in 1 move via simple URL copy-paste or choose from ready-to-go curated tools
- Run Nextflow, Cromwell-WDL and containerised pipelines in 3 clicks, leveraging enterprise-grade security, access controls, cost management, and advanced data management.
- Scale and reproduce workflows with cutting-edge monitoring and controls. FAIR compliance ensures easy cloning and retention of analyses for reproducibility, supporting future inquiries effortlessly and efficiently.
- Get the full power of JupyterLab, Spark Notebooks, RStudio, from data to results in one-unified experience

5. User exports analysis result, admin approves export requests keeping sensitive data secure
Lifebit’s TRE is configured by default to prevent data exports or downloads, keeping patient data securely within your environment. Users can submit export requests for analysis results, which admins review through the Lifebit TRE’s unique and pioneering AirlockTM system, approving or denying based on data sensitivity. This provides the world’s fastest, most compliant and most secure result data export process.

Collaborative and secure research, discovery and translation
Segment solutions
Lifebit’s Trusted Research Environment offers a broad range of use cases across segments
Public Sector Initiatives
TRE enabling controlled access to biomedical data
Controlled data access & sharing
Population genomics research
Cohort building & analysis
Data commercialization
Federal Health
TRE for sensitive data analysis
Controlled data access & sharing
Internal R&D
Cohort building & analysis
Data Providers
TRE for secure and controlled clinico-genomic and real world data
Controlled data access & sharing
Data commercialization
Health Nonprofit
TRE for storage, computing and multi-omics data analysis
Multi-omics data analysis
Population genomics research
Controlled data access & sharing
Data commercialization
Pharma & Biotech
TRE for multi-modal data analysis
Multi-omics data analysis
NGS data processing
Target identification & discovery
Patient subtyping stratification
Controlled data access & sharing
Securely protecting your sensitive biomedical data.
End-to-End Data Governance and Security by Design
based on the most advanced federated architecture in the industry







Featured news and events
Ready to collaborate on distributed data?
Contact Lifebit today and discover how our federated data solutions can accelerate your research.
We’ll respond as soon as possible.
Lifebit will only use your personal information to provide information about our products and services. From time to time we may email you, which you may unsubscribe from at any time. To learn more, see our Privacy Policy and Cookie Policy.
FAQs
Data federation is a software process that enables numerous databases to work together as one. Using this technology is important for accessing sensitive biomedical health data, as the data remains within appropriate jurisdictional boundaries, while metadata (information about the data) is centralised and searchable.
Data federation is an alternative to a model in which data is moved or duplicated then centrally housed – when data is moved it becomes vulnerable to interception and movement of large datasets is often very costly for researchers. Instead, approved users may access the data via linking technologies such as Application Programming Interfaces, or APIs.
A Federation Platform-as-a-Service (FedPaaS) is a secure, cloud-based service model that enables organizations to access and analyze data directly in their own cloud environment—without moving or duplicating the data. Unlike traditional bioinformatics platforms that require data to be transferred to the provider’s cloud account, Lifebit’s FedPaaS keeps data and computation within the organization’s own infrastructure.
This model allows organizations to:
Maintain Full Control: Data stays in your organization’s cloud account, giving you full ownership and control without data exposure to shared environments.
Ensure Data Residency Compliance: Data remains within your jurisdiction and infrastructure, which is essential for compliance with data residency and privacy regulations.
Optimize Cloud Costs: Since data remains in your cloud account, you avoid the added costs and markups of external cloud storage and compute fees, and you leverage your own provider discounts.
Avoid Costly Data Transfers: If your relationship with the FedPaaS provider changes, there are no egress fees or data migrations needed—your data always remains in your environment.
With Lifebit’s platform patient level data never moves thanks to its enterprise-grade federated architecture that keeps data in-place, and that adheres to the highest global security standards, including FedRamp, GDPR, HIPAA, ISO, and SOC II. We also implement the 5 Safes Framework to ensure strict data residency and secure access, making us the trusted choice for government and regulated industries.