
Sharing Smarter: Your Guide to Federated Data and Interoperability
Federated data sharing: Your Ultimate 2025 Guide
Why Traditional Data Sharing Fails in Healthcare and Research
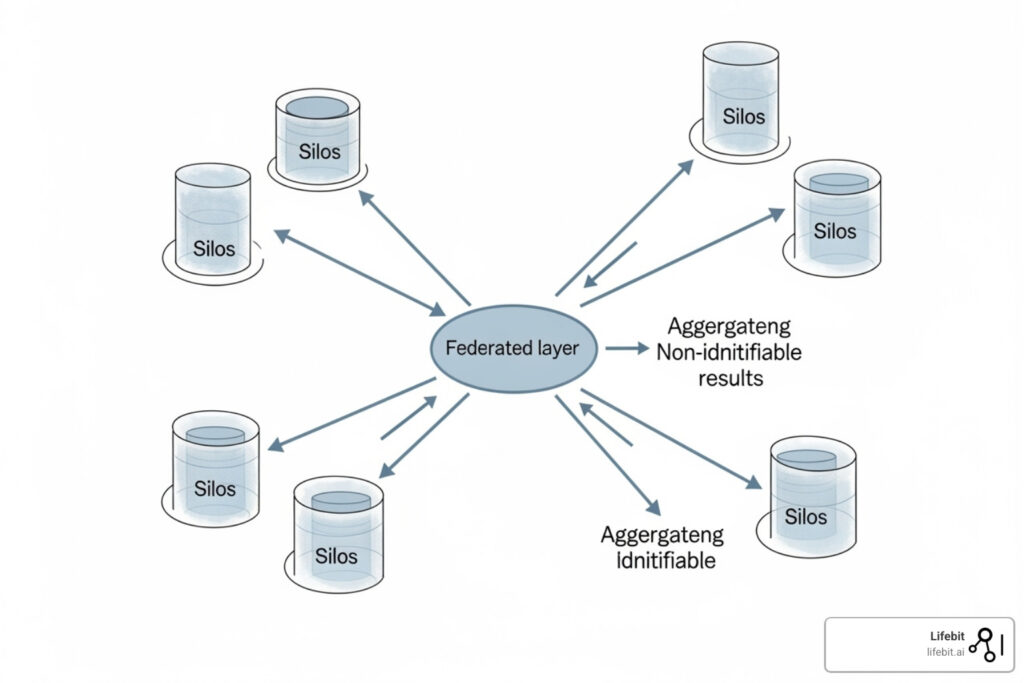
Federated data sharing enables secure analysis across distributed datasets without moving sensitive data. Instead of centralizing data into a single repository, queries are sent to where the data lives, and only aggregated, non-identifiable results are returned. This model fundamentally inverts the traditional paradigm of moving data to computation.
Key Principles of Federated Data Sharing:
- Data stays in place: Sensitive datasets are never copied or moved from the owner’s secure environment. This respects data sovereignty, minimizes the risk of data breaches during transit, and gives data owners ultimate control.
- Queries travel to data: Analysis code, packaged in a secure container, is sent to each data source for local execution. This brings the computation to the data, rather than the other way around.
- Only safe results return: Outputs are aggregated and anonymized before being returned to the researcher. This ensures that no individual-level or potentially re-identifiable information ever leaves the data owner’s control.
- Governance controls access: Strict, auditable approval workflows and permissions are enforced at every step. Data owners grant access on a per-project basis, ensuring data is only used for its intended purpose.
- Privacy by design: The entire system is architected with privacy as a core requirement, not an add-on. This includes using Privacy-Enhancing Technologies (PETs) and secure-by-default configurations.
The numbers tell a stark story: an estimated 97% of hospital data goes unused due to privacy regulations and data silos. Traditional data sharing—which requires creating a central data lake or warehouse—is fraught with challenges. It involves lengthy and complex legal agreements (Data Use Agreements or DUAs) that can take months or even years to negotiate. Furthermore, it creates a single, high-value target for cyberattacks and raises significant privacy risks, as data custodians lose direct control once the data is copied. This friction leaves invaluable insights trapped within institutional walls, slowing medical research and limiting our ability to tackle global health challenges like pandemics, cancer, and rare diseases.
The solution is to bring computation to the data. This federated approach allows researchers to run analyses across multiple institutions while keeping sensitive information secure. Organizations maintain full control over their data, acting as sovereign nodes in a collaborative network. This allows them to contribute to powerful, large-scale research that can improve patient outcomes worldwide, without compromising on security or compliance.
As Maria Chatzou Dunford, CEO and Co-founder of Lifebit, I’ve seen how federation can open up the value of distributed health data while maintaining the highest privacy and security standards.
 and federated data sharing (sending questions to the data) - federated data sharing infographic")
What is Federated Data Sharing and Why Does It Matter?
Imagine unlocking insights from millions of patient records and clinical trials scattered across the globe—without ever moving a single piece of sensitive data. This is what federated data sharing makes possible.
At its core, federation brings the analysis to the data, a necessary shift in a world with increasingly strict privacy regulations. The scale of untapped potential is staggering. The World Economic Forum found that 97% of hospital data goes unused, locked away in institutional silos.
This unused data perpetuates and exacerbates healthcare inequities. Most large-scale genomic studies focus on European populations, meaning that resulting diagnostics and treatments are often less effective for underrepresented groups. For example, a drug’s efficacy or side-effect profile can vary significantly across different ancestries due to genetic differences. Federated data sharing directly tackles this by enabling analysis across diverse, distributed populations without compromising privacy. The statistical benefits are remarkable: a tenfold increase in sample size can lead to a 100-fold increase in genetic discoveries. Federation is also more sustainable, eliminating the significant financial and environmental costs (carbon footprint) of transferring and storing petabyte-scale datasets.

Defining the Federated Approach
Instead of asking everyone to bring their data to a central location, federated data sharing sends the analysis to each location and collects only the summary results. The principle is simple: code travels to the data, not the other way around. Analysis happens locally within each institution’s secure perimeter, and only aggregated results are shared, keeping raw data in its controlled environment.
This contrasts sharply with other models:
- Traditional Data Download: Creates multiple copies of sensitive data, increasing the attack surface and compliance burden. It often violates data residency laws and gives the data owner little control after the transfer.
- Remote Desktop Access: Keeps data in place but is a brittle, unscalable solution. It provides a user with broad access to a system, is difficult to audit, and does not support complex, multi-institutional computational workflows.
Federation solves these problems by allowing governed, auditable, and programmatic remote querying, where only Level 2 summary outputs—aggregated, privacy-preserving results—are shared.
The Problems Solved by Federation
Federation is often the only practical solution for several critical challenges:
- Highly sensitive data: Genomic sequences, electronic health records (EHRs), and clinical trial data are subject to strict privacy regulations. Federation keeps this data secure in its original, trusted environment.
- Immovable datasets: National sovereignty laws and regulations like GDPR in Europe or HIPAA in the US often prohibit moving personal data across borders. Research shows how GDPR can impact data sharing, making federation an essential workaround for international collaboration.
- Legal and ethical barriers: Federation simplifies compliance by ensuring only non-identifiable, aggregated results cross organizational boundaries, dramatically reducing the legal overhead of negotiating complex data sharing agreements.
- Sample size for rare diseases: No single institution has enough patients for statistically powerful research on rare conditions. Federation allows researchers to combine insights from large, distributed cohorts. This is critical for reclassifying variants of uncertain significance (VUS)—genetic changes whose clinical impact is unknown. By analyzing a VUS across thousands of patients, researchers can gather enough evidence to reclassify it as pathogenic or benign, providing patients and clinicians with more definitive answers and actionable diagnoses.
The Architecture of a Data Federation: Components and Workflow
Building a successful federated data sharing system connects isolated data islands into a cohesive network, all while respecting each owner’s sovereignty and control. The architecture creates a unified experience for researchers, guided by the FAIR principles: making data Findable, Accessible, Interoperable, and Reusable.
, and data catalogs - federated data sharing")
Key roles in a federation include Data Owners (the institutions that are legal guardians of the data), Data Stewards (technical and policy experts who manage data quality and access), Platform Operators (who manage the federated infrastructure), and Researchers (end-users who submit queries).
Core Architectural Components
The heart of a federated system includes several key components working in concert:
- Federated Database Management System (FDBMS): This is the central conductor. It receives a global query from a researcher, breaks it down into sub-queries for each relevant data source, orchestrates their execution, and reassembles the partial results into a final, unified answer. It does not store the data itself, only manages the query process.
- Connectors: These are lightweight software agents installed at each data source. They act as translators, allowing the FDBMS to communicate securely with diverse underlying data systems (e.g., SQL databases, NoSQL stores, data lakes, file systems) without requiring changes to those systems.
- Virtualization Layer: This layer creates a unified, logical view of all distributed data. It abstracts away the complexity of the underlying physical storage and formats, allowing researchers to write a single query as if they were accessing one large, centralized database.
- Data Catalog: A centralized, searchable repository of metadata (data about the data). It describes what datasets are available in the federation, their variables, provenance, and access conditions. This is the cornerstone of making data Findable.
- Metadata Management: The set of processes and tools used to create, maintain, and govern the metadata in the data catalog. High-quality metadata is essential for researchers to trust and effectively use the federated data.
- Ontologies and Taxonomies: A shared vocabulary (e.g., SNOMED for clinical terms, OMOP Common Data Model) that ensures data is semantically consistent across different sites. This is crucial for making data Interoperable, as it ensures that a query for “myocardial infarction” retrieves the correct data from all sites, regardless of how it is locally coded.
- Harmonization Pipelines: Automated workflows that transform raw data into a standardized, interoperable format based on the chosen ontology. These pipelines are typically run locally by the data owner to prepare data for inclusion in the federation.
Understanding the End-to-End Workflow of federated data sharing
The journey from data discovery to insight follows a secure, orchestrated workflow:
- Dataset Findability: Researchers use the central data catalog to explore available datasets. They can filter and search based on rich metadata (e.g., cohort size, data type, patient demographics) to identify data relevant to their hypothesis.
- Data Access Request: Once relevant datasets are found, the researcher submits a formal proposal through the platform. This typically includes their research question, hypothesis, analysis plan, and the specific data variables required.
- Approval Workflow: The request is automatically routed to the appropriate Data Access Committee (DAC) for each dataset. The DAC, composed of representatives from the data-owning institution, reviews the request against ethical and institutional policies. DACs play a crucial role in governing access to sensitive data.
- Query Execution: Upon approval, the researcher is granted permission to submit their analysis or code to the platform. The system uses “query push-down” to send the computation securely to each data source’s location for local execution on the raw data.
- Results Aggregation: Only the computed, aggregated results (e.g., a p-value, a regression coefficient, a count of patients) are returned to the central system and then to the researcher. Individual-level data is never exposed or moved.
Dataset Findy and Citation
Making distributed datasets findable and citable is essential for reproducible science. This is achieved through metadata standards like Dublin Core and DataCite, which provide a consistent way to describe data. Dataset registration in a central catalog makes data visible, while Digital Object Identifiers (DOIs) provide persistent, unique identifiers that ensure datasets can be reliably cited in publications, just like articles. Integrating with researcher profiles via ORCID improves attribution and helps track the impact of data contributions. Finally, indexing with services like Google Dataset Search and DataCite, as detailed by platforms like the Federated Research Data Repository (FRDR), increases visibility while maintaining strict access controls.
Governance, Trust, and Legal Frameworks for Federated Data Sharing
Successful federated data sharing depends less on technology and more on establishing trust, creating clear governance, and navigating complex privacy laws. Organizations must be confident that they can collaborate on insights while keeping their most sensitive data secure and under their control.
This foundation is built on solid data governance policies. These are not just documents, but a comprehensive framework that includes clear rules for onboarding new partners, a binding code of conduct for all participants, a schedule for regular auditing of queries and access logs, and a pre-defined incident response plan. Legally binding Data Use Agreements (DUAs) and transparent consent models are critical for defining the scope of permitted research and ensuring alignment with participant expectations.
 in federated data sharing, with icons representing data owners, a central coordinator, and direct connections between participants - federated data sharing")
Establishing Trust and Controlling Access
Trust is the currency of federation. There are three main models for establishing it, often used in combination:
- Centralized trust: A single, highly trusted organization (e.g., a national health institute or a leading research university) acts as the coordinator, vetting participants, managing access, and enforcing rules. This model is efficient but relies heavily on the reputation of the central body.
- Decentralized trust: Responsibility is shared among a consortium of participants who collectively make decisions based on agreed-upon protocols, often managed through a steering committee. This model is more democratic but can be slower to make decisions.
- Pairwise trust: Organizations form direct, bilateral relationships and negotiate access terms one-on-one. This is flexible but does not scale well to a large network.
Access control is the technical enforcement of trust. It relies on strong authentication (verifying a user’s identity, often with multi-factor authentication) and authorization (determining what an authenticated user is allowed to do). Role-Based Access Control (RBAC) is a common starting point, assigning permissions based on roles (e.g., “researcher,” “data steward”). However, Attribute-Based Access Control (ABAC) offers more granular, dynamic control by defining policies based on attributes of the user (e.g., their institution, training status), the data (e.g., sensitivity level), and the context (e.g., time of day, approved project ID).
Navigating the Legal Landscape
Federation is specifically designed to navigate complex privacy regulations like GDPR and HIPAA. Under GDPR, a controller determines the purposes and means of processing personal data, while a processor handles data on the controller’s behalf. In a federation, each data-owning institution remains the sole controller of its data.
The beauty of federated data sharing is that it minimizes legal complexity. Since raw, identifiable data never leaves the owner’s environment, the central platform and researchers do not become controllers or processors of that raw data. This dramatically reduces the legal burden and simplifies cross-border data transfers. Because only aggregated, non-identifiable results cross borders, they are not typically considered personal data under regulations like GDPR, respecting data residency laws while enabling international collaboration. Similarly, under HIPAA in the United States, this approach helps covered entities meet the “minimum necessary” standard and ensures that any data leaving the environment has been properly de-identified according to the Safe Harbor or Expert Determination methods.
Ethical Considerations and Transparency
Beyond legal compliance, responsible federation requires a deep commitment to ethics and transparency.
- Explainability of outputs: To ensure scientific validity and trust, researchers must be able to understand and reproduce how results were derived. The federated system must provide clear provenance for all outputs.
- Participant communication: Patients and research participants have a right to know how their data is being used. Federations should develop clear, accessible materials explaining the distributed model and the safeguards in place.
- Indigenous data sovereignty: Federation can support the right of indigenous communities to maintain control and governance over their data. This involves embracing principles like the CARE Principles (Collective Benefit, Authority to Control, Responsibility, Ethics), which ensure data use benefits the community and respects their authority.
- Equity of access: By lowering the technical and financial barriers to entry, federation can democratize research opportunities. This allows smaller institutions and researchers from low- and middle-income countries to participate in and lead groundbreaking studies, fostering a more inclusive global research ecosystem.
Advanced Privacy and Security in a Federated System
In a federated system, security is not an afterthought—it’s built into the foundation. This privacy by design approach means every component is engineered for security, from the network protocols to the application layer. It relies on the principle of data minimization—processing only the data absolutely necessary for a given task—and employs robust cybersecurity controls to protect every interaction within the network.
 work in a federated context, showing data encrypted and computations performed without decryption, and results aggregated securely - federated data sharing infographic")
Privacy-Enhancing Technologies (PETs)
PETs are a class of sophisticated cryptographic and statistical techniques that enable secure analysis on confidential data, forming the technical bedrock of trust in a federation.
- Secure Multiparty Computation (SMC): Allows multiple parties to jointly compute a function over their inputs without revealing those inputs to each other. For example, three hospitals could calculate the average age of their diabetic patients without any hospital learning the ages from the others.
- Homomorphic Encryption (HE): A powerful technique that enables computations directly on encrypted data. Data is encrypted at the source, computations (like statistical models) are run on the ciphertext, and only the final encrypted result is shared and decrypted. While computationally intensive, research has shown this can provide a 30x speedup for certain genomic analyses.
- Differential Privacy (DP): Provides a formal mathematical guarantee of privacy by adding precisely calculated statistical noise to query results. This makes it impossible to determine whether any single individual’s data was included in the computation. This is managed through a “privacy budget” (epsilon), which limits the total number of queries that can be run to prevent privacy loss through repeated analysis.
- Trusted Execution Environments (TEEs): Hardware-based secure enclaves (like Intel SGX or AMD SEV) that create a protected, isolated area in a processor. Code and data loaded into a TEE are inaccessible and invisible even to the host system’s administrator, providing a verifiable guarantee that the computation is running as intended and the data is not being exposed.
Key Privacy Threats in federated data sharing
Even with advanced protections, federated systems must be designed to guard against several specific threats:
- Re-identification attacks: An adversary attempts to combine anonymous aggregated results with public information (e.g., voter registries, social media) to re-identify individuals in the dataset.
- Linkage attacks: Connecting different datasets through common attributes to reveal sensitive information. For example, linking a de-identified hospital dataset with a public dataset using quasi-identifiers like ZIP code, birth date, and gender.
- Inference attacks: Using clever queries to infer private information. This includes membership inference (determining if a specific person’s data was used in an analysis) and property inference (learning sensitive properties of the training data that are not explicitly released).
- Model poisoning: A malicious participant in a federated learning scenario injects corrupted data to intentionally degrade a shared model’s performance or create a backdoor for future exploitation.
- Traditional cyberattacks: Federated systems are still software and must be hardened against common threats like SQL injection, cross-site scripting, and man-in-the-middle attacks on the network.
Output and Extraction Controls
The final and most critical line of defense is controlling what information leaves the secure environment. Extraction controls are automated and manual checks that ensure only safe, aggregated results are released.
- Safe results: The system is designed to return only highly aggregated, statistically protected outputs by default.
- Query whitelisting: Only pre-approved, vetted types of analyses and commands are allowed to run, preventing users from executing arbitrary code that could leak data.
- K-anonymity thresholds: The system automatically checks that any group described in a result includes at least ‘k’ individuals (e.g., k=5). If a query result refers to fewer than ‘k’ individuals, it is suppressed to prevent singling someone out.
- Result suppression and noise addition: In addition to k-anonymity, the system can automatically hide small cell counts in contingency tables or add noise (as in differential privacy) to obscure individual contributions.
Crucially, a strict Airlock process provides a final checkpoint. This often requires a designated data steward to manually review all outgoing results against a clear policy, ensuring that no raw or individual-level data ever leaves the secure environment. Even system logs are designed to be PII-safe, stripping any personal information to protect privacy during routine monitoring and auditing.
From Pilot to Production: A Practical Implementation Guide
Transitioning a federated data sharing system from a pilot to a full production environment is a journey that requires careful planning across technical, financial, and social dimensions. Key technical considerations include minimizing latency and managing bandwidth through smart query optimization, caching, and parallel execution. Aligning with community-driven interoperability standards, like those from the Global Alliance for Genomics and Health (GA4GH) (e.g., Passport and Data Use Ontology), is essential for long-term scalability and collaboration.
Financial models must be sustainable and account for the total cost of ownership, including infrastructure, governance, and user support. While there is an initial investment, federation can significantly reduce long-term expenses by avoiding the massive costs of data duplication, storage, and transfer. Models can range from consortium membership fees to pay-per-query systems. Success metrics should evolve beyond simple usage statistics to focus on outcomes like reduced query turnaround time, the number and diversity of federated datasets, new collaborations formed, and ultimately, the impact on research and patient care.
| Feature | On-Prem Deployment Options |
|---|---|
| Control | Full control over infrastructure, data, and security policies |
| Compliance | Easier to meet strict regulatory requirements (HIPAA, GDPR) |
| Performance | Optimized for local network speeds and custom hardware |
| Cost | Higher upfront costs, predictable ongoing expenses |
| Scalability | Limited by physical infrastructure, requires planning for growth |
| Maintenance | Full responsibility for updates, security patches, and support |
Getting Started: Piloting and Implementation
A minimal viable federation is the smartest way to start, de-risking the project and building momentum through early wins.
- Start in a sandbox environment: Use a secure, isolated space with a federated platform to allow technical teams and potential users to experiment with capabilities without risk to production data.
- Use synthetic data: Test the entire end-to-end workflow, from data harmonization to federated analysis, using artificially generated data that mimics the structure and properties of real datasets without any privacy concerns. This is invaluable for training users and refining processes.
- Implement a staged rollout: Begin with a small group of 2-3 trusted data owners and a handful of friendly researchers. Use this initial phase to refine governance policies, technical configurations, and support documentation before expanding the network.
Leveraging reference architectures and modern tooling can dramatically accelerate deployment. Modern federated platforms are designed for a minimal technical footprint, using lightweight connectors that don’t disrupt existing IT systems. This non-disruptive integration is crucial for encouraging participation from resource-strapped institutions.
Operational Best Practices
For long-term success and scalability, establish solid operational practices from day one:
- Manage heterogeneity: Use common data models (e.g., OMOP) and automated harmonization pipelines to address differences in data formats and terminologies. Empower data stewards to oversee this process.
- Optimize queries: Use a query engine that intelligently pushes computations down to the source systems and optimizes the execution plan to preserve privacy and maximize performance.
- Define SLAs: Set clear Service Level Agreements for platform availability, query response times, and user support to build trust and manage expectations.
- Train and support users: A federation is as much a community as a technology. Provide comprehensive training and responsive support to ensure all users and administrators understand security protocols, compliance requirements, and platform operations.
- Manage the data lifecycle: Establish clear policies for data curation, versioning, preservation, and eventual retirement.
- Support batch and streaming data: Design the architecture to accommodate both historical analysis on static datasets and real-time analytics on streaming data feeds.
- Integrate with downstream tools: Ensure that the aggregated, safe results from the federation can be seamlessly exported and used in researchers’ preferred data science environments (e.g., RStudio, Jupyter notebooks).
Finally, avoid common pitfalls like scope creep, returning overbroad outputs that risk re-identification, insufficient logging for audits, and poor schema mapping that leads to erroneous results.