
Life Sciences and Oncology Analytics: How Data is Transforming Cancer Care
Why Oncology Data Analytics is Revolutionizing Cancer Care
Oncology data analytics is the systematic collection, processing, and analysis of cancer-related data to improve patient outcomes, accelerate drug findy, and optimize treatment decisions. This field encompasses:
- Genomic data analysis – Understanding tumor mutations and biomarkers
- Clinical data integration – Combining electronic health records with treatment outcomes
- Real-world evidence generation – Analyzing patient data outside clinical trials
- Multiomics approaches – Integrating genomic, proteomic, and clinical datasets
- AI-powered insights – Using machine learning to predict treatment responses
Cancer is an extraordinarily complex and heterogeneous disease, but we’re witnessing an unprecedented big-data revolution across the cancer research-care continuum. The molecular characterization of cancer through genomics, data from multiomics technologies, and real-world patient data are creating massive opportunities to transform how we diagnose, treat, and prevent cancer.
The numbers are staggering. The Cancer Genome Atlas (TCGA) alone has generated over 2.5 petabytes of genomic, epigenomic, transcriptomic, and proteomic data from more than 20,000 cancer samples spanning 33 cancer types. Looking ahead, it’s estimated that 100 million to 2 billion human genomes could be sequenced by 2025, producing up to 1 zettabase of sequence data per year.
But here’s the challenge: data analysis has lagged significantly behind data generation. Currently, of the 8 % of cancer patients who qualify for big-data-driven targeted therapies, only 5 % actually benefit. This gap between data generation and patient benefit represents both our biggest challenge and our greatest opportunity.
I’m Maria Chatzou Dunford, CEO and Co-founder of Lifebit, with over 15 years of expertise in computational biology, AI, and health-tech entrepreneurship focused on changing global healthcare through federated oncology data analytics. My work has centered on building cutting-edge platforms that empower precision medicine and biomedical data integration across secure, compliant environments.

Simple guide to oncology data analytics:
Defining the Landscape: What is Oncology Data Analytics?

Think of oncology data analytics as the art and science of turning cancer’s complexity into clarity. We’re living in an era where every aspect of cancer care generates data – from the molecular fingerprint of a tumor to how a patient feels after treatment. The magic happens when we bring all these pieces together.
What makes this field so exciting is how we can now weave together completely different types of information. Traditional clinical records that doctors have used for decades can now dance with cutting-edge genomic data to reveal insights that neither could provide alone. It’s like having a conversation between your patient’s medical history and their tumor’s genetic blueprint.
The challenge isn’t just collecting this data – it’s making sense of it all. That’s where real-world data becomes crucial. This includes everything from electronic health records to how patients actually respond to treatments outside the controlled environment of clinical trials. When we combine this with sophisticated clinical data integration platforms, we start to see the complete picture of each patient’s cancer journey.
The Spectrum of Oncology Data
The beauty of modern oncology data analytics lies in its diversity. We’re no longer limited to just looking at lab results or imaging scans – we can now examine cancer at every level, from molecules to real-world patient experiences.
Genomics data from DNA sequencing helps us understand which mutations are driving a patient’s cancer. Modern whole-genome sequencing can identify millions of genetic variants per patient, creating detailed molecular maps that reveal not just what mutations are present, but how they interact with each other. These interactions often determine whether a patient will respond to targeted therapies like EGFR inhibitors or immune checkpoint blockers.
Transcriptomics reveals which genes are actually active in the tumor at any given moment. Unlike genomic data, which shows us the static blueprint, transcriptomic analysis captures the dynamic activity of cancer cells. This is particularly valuable for understanding how tumors evolve during treatment and develop resistance mechanisms. Single-cell RNA sequencing has revolutionized this field by allowing us to examine individual cancer cells rather than averaging across entire tumor samples.
Proteomics shows us the proteins that are being produced and could serve as targets for new treatments. Proteins are the actual workhorses of cancer cells, and understanding protein expression patterns helps predict drug responses more accurately than genomic data alone. Mass spectrometry-based proteomics can now identify and quantify thousands of proteins simultaneously, creating detailed functional profiles of tumor behavior.
Metabolomics adds another crucial layer by examining the small molecules and metabolic pathways that fuel cancer growth. Cancer cells often reprogram their metabolism to support rapid growth and survival, creating unique metabolic signatures that can be targeted therapeutically. This field has revealed how tumors adapt to different tissue environments and treatment pressures.
But it doesn’t stop there. Clinical data from electronic health records tracks how patients respond to treatments over time, capturing everything from laboratory values to physician assessments of treatment response. Imaging data from CT scans, MRIs, and PET scans shows us exactly how tumors change in size, shape, and metabolic activity. Advanced imaging analytics can now detect subtle changes that human radiologists might miss, enabling earlier detection of treatment response or progression.
Real-world data from wearables and patient surveys captures the human side of cancer care – how treatments affect daily life and quality of life. This includes data from fitness trackers that monitor activity levels and sleep patterns, smartphone apps that track symptoms and medication adherence, and patient-reported outcome measures that capture the subjective experience of living with cancer.
The real breakthrough comes when we integrate all these data types. A single patient’s complete molecular profile can generate 2-4 terabytes of data or more. That’s like having a detailed biography written at the cellular level, telling the story of how cancer develops and responds to treatment.
The Scale of the Data: From Petabytes to Zettabytes
The numbers in oncology data are mind-boggling, and they’re growing exponentially. The Cancer Genome Atlas (TCGA) pioneered this data revolution, creating the world’s largest collection of cancer genomic data. Since 2006, TCGA has analyzed over 20,000 primary cancers across 33 cancer types, generating more than 2.5 petabytes of data.
What’s remarkable is that all this TCGA data remains publicly accessible for researchers worldwide. This open approach has accelerated cancer research in ways we couldn’t have imagined two decades ago. The data has been used in over 15,000 research publications and has directly contributed to the development of numerous FDA-approved cancer treatments.
But TCGA was just the beginning. We’re now entering an era where the entire field generates petabytes of data daily. The UK Biobank alone contains genetic and health information from over 500,000 participants, with plans to sequence complete genomes for all participants. Similar initiatives are underway globally, including the All of Us Research Program in the United States, which aims to collect data from one million diverse participants.
By 2025, experts predict we could see up to 1 zettabase of sequence data generated annually. To put that in perspective, that’s roughly equivalent to digitizing every book ever written – and then multiplying that by several million. This exponential growth is driven by decreasing sequencing costs, which have fallen faster than Moore’s Law, and increasing adoption of genomic medicine in routine clinical care.
The computational challenges are equally staggering. Processing and analyzing a single whole-genome sequence requires significant computational resources, and storing the results requires robust data management infrastructure. When multiplied across millions of patients and integrated with clinical, imaging, and real-world data, the computational requirements become enormous.
This data explosion creates both incredible opportunities and real challenges. On one hand, we have unprecedented insight into how cancer works at the molecular level. On the other hand, we’re reaching a point where even the most sophisticated research teams struggle to make sense of such vast amounts of information without proper collaboration tools and theoretical frameworks.
The key is not just collecting more data, but developing smarter ways to analyze and integrate it. That’s where the future of oncology data analytics lies – in platforms that can handle this scale while keeping the focus on what matters most: improving patient outcomes.
The Transformative Impact of Oncology Data Analytics Across the Cancer Care Continuum

Something remarkable is happening in cancer care right now. Oncology data analytics is breaking down the walls between the research lab and the patient’s bedside, creating a more connected and personalized approach to fighting cancer.
Gone are the days when we treated all cancer patients the same way. Today’s data-driven approach touches every aspect of cancer care – from drug findy in the lab to patient stratification in the clinic, from treatment planning in the hospital to clinical research across institutions.
The change is most visible in how we’re moving away from the old “one-size-fits-all” mentality. Through large-scale data analysis, we can now pinpoint exactly which patients will benefit from specific treatments. This means better outcomes for patients and fewer unnecessary side effects.
The Role of Oncology Data Analytics in Precision Medicine
Here’s where oncology data analytics really shines: precision medicine. Think of it as creating a detailed fingerprint for each patient’s cancer, then matching that fingerprint to the most effective treatment.
Through molecular profiling of tumor samples, we’ve uncovered entirely new ways to classify cancers that go beyond traditional tissue types. The results speak for themselves – since 2016, we’ve seen four biomarker-driven, tumor-agnostic approved treatments that work across 20 different cancer types.
These breakthrough approvals represent a fundamental shift in how we think about cancer treatment. Traditional oncology focused on where the cancer originated – lung cancer, breast cancer, colon cancer. But molecular profiling revealed that cancers with similar genetic alterations often respond to the same treatments regardless of their tissue of origin. Pembrolizumab for microsatellite instability-high tumors, larotrectinib for NTRK fusion-positive cancers, and entrectinib for ROS1 rearrangements exemplify this new paradigm.
AI-powered biomarker findy is opening doors we never thought possible. Take the KRAS protein, for example. For decades, scientists called it “undruggable.” Then in 2021, the first KRAS inhibitor was approved, thanks to data analytics that revealed new ways to target this previously impossible protein. The development of sotorasib (Lumakras) for KRAS G12C mutations demonstrates how sophisticated molecular analysis can identify previously hidden therapeutic vulnerabilities.
The impact extends beyond individual biomarkers to complex molecular signatures. Multi-gene assays like Oncotype DX for breast cancer and Foundation Medicine’s comprehensive genomic profiling tests analyze dozens or hundreds of genes simultaneously to predict treatment responses and prognosis. These tests have fundamentally changed treatment decisions for thousands of patients, often sparing them from unnecessary chemotherapy or identifying them as candidates for targeted therapies.
Liquid biopsies represent another application of oncology data analytics. By analyzing circulating tumor DNA in blood samples, we can now monitor treatment response, detect minimal residual disease, and identify emerging resistance mutations without invasive tissue biopsies. Companies like Guardant Health and Foundation Medicine have developed sophisticated analytical platforms that can detect minute quantities of tumor DNA among the vast background of normal DNA in blood samples.
But here’s the sobering reality: we’re still not reaching enough patients. Analysis across 11 countries showed that only 20% of patients received treatment informed by molecular tumor boards between 2014 and 2020. This gap between findy and delivery is exactly what drives innovation in platforms that make analytics more accessible to clinicians.
The field continues to evolve rapidly, with research into molecular profiling showing us how to better match patients with their ideal treatments based on their unique molecular signatures. Emerging approaches like spatial transcriptomics and single-cell analysis are providing even more detailed insights into tumor heterogeneity and the tumor microenvironment.
Optimising Clinical Trials
Clinical trials are where hope meets science, but they’ve traditionally been frustratingly inefficient. The numbers are stark: only 3-5% of clinical trial enrollments yield the results we’re looking for, while developing a successful cancer drug takes over 10 years and costs up to $3 billion.
Oncology data analytics is changing this story in powerful ways. Patient cohort identification now happens with precision we never had before, helping researchers find exactly the right patients for their studies. Advanced algorithms can scan electronic health records across multiple institutions to identify patients who meet complex eligibility criteria, dramatically reducing enrollment timelines.
Adaptive platform trials like the I-SPY2 breast cancer study use real-time data to test multiple treatments simultaneously, making trials smarter and more efficient. These trials can add or drop treatment arms based on interim results, allowing researchers to focus resources on the most promising approaches while quickly abandoning ineffective treatments.
The I-SPY2 trial serves as a perfect example of how data analytics can revolutionize clinical research. By stratifying patients based on their molecular profiles and adapting the trial design based on incoming data, researchers can test multiple approaches simultaneously while learning continuously. The trial has evaluated over 20 experimental treatments and has successfully graduated several to phase III trials, dramatically accelerating the drug development process.
Master protocols represent another innovation enabled by sophisticated data analytics. These umbrella and basket trials can test multiple treatments across multiple cancer types simultaneously, sharing control arms and infrastructure to improve efficiency. The NCI-MATCH trial, for example, assigns patients to treatment arms based on their tumor’s molecular profile rather than their cancer type, enabling precision medicine approaches that would be impossible with traditional trial designs.
One of the most exciting developments is using external control arms – essentially using real-world data as historical controls instead of giving patients placebos. This approach can speed up trials while ensuring more patients get potentially life-saving treatments. Regulatory agencies like the FDA are increasingly accepting these approaches for rare cancers where traditional randomized trials would be impractical.
Through clinical trial success with secure data platforms, we’re seeing faster enrollment, better patient matching, and more efficient trial designs that dramatically reduce the time from findy to patient benefit.
Advancing Radiation Oncology
Radiation oncology presents unique challenges that oncology data analytics is perfectly positioned to solve. Every tumor responds differently to radiation, even within the same cancer type, and sometimes even within the same tumor.
Tumor response variability has always puzzled radiation oncologists, but analytics are helping us understand why some areas of a tumor respond while others don’t. This insight is particularly valuable for stereotactic ablative radiotherapy (SBRT), where precision is everything.
Imaging precision has dramatically improved through machine learning algorithms that can identify targets and plan treatments with unprecedented accuracy. This is especially important for lung cancer, where tumors move with breathing and require incredibly precise targeting. Advanced algorithms can now predict tumor motion and adjust treatment delivery in real-time.
Treatment planning now incorporates vast amounts of data from previous patients with similar tumors, helping doctors optimize dose distribution and verify treatments in real-time. Unlike traditional approaches that treated spatial information as an afterthought, modern spatial data analysis incorporates detailed spatial information from multiple imaging types.
Research from institutions like UBC’s Medical Physics and Data Analytics Cluster demonstrates how these data-driven approaches are improving treatment outcomes while reducing side effects through more precise, personalized treatment planning.
The change across radiation oncology shows how oncology data analytics doesn’t just improve outcomes – it fundamentally changes how we think about treating cancer, making each treatment as unique as the patient receiving it.
Overcoming the Problems: Key Challenges in Oncology Big Data

Let’s be honest – oncology data analytics sounds amazing in theory, but the reality is messier than we’d like to admit. While we’ve become incredibly skilled at generating massive amounts of data, we’ve struggled to turn that data into real benefits for patients sitting in oncology clinics around the world.
The numbers tell a sobering story. We have access to more cancer data than ever before, yet only 5% of eligible patients actually benefit from targeted therapies. This gap between data generation and patient benefit represents both our biggest frustration and our greatest opportunity.
The core problem is surprisingly simple: we’ve been so focused on collecting data that we forgot to build the bridges needed to connect it all together. Understanding these challenges of using real-world data in research is the first step toward creating solutions that actually work for patients.
Ensuring Data Quality and Standardisation
Poor data quality is like trying to bake a cake with spoiled ingredients – no matter how sophisticated your recipe, you’re not going to get good results. In oncology data analytics, this problem shows up in several frustrating ways.
Biospecimen quality issues can completely derail research efforts. When biospecimens aren’t properly collected, stored, or processed, researchers end up chasing ghost signals that look like breakthrough findies but are actually just processing artifacts. The NCI’s best practices for biospecimens provide excellent guidelines, but getting everyone to follow them consistently remains a challenge.
Unstructured data presents another major headache. Critical information about patient outcomes, treatment responses, and side effects often sits buried in pathology reports, clinical notes, and imaging studies. This “fuzzy data” requires sophisticated natural language processing to extract meaningful insights, but many institutions lack the technical infrastructure to handle this properly.
The reproducibility crisis in AI-driven cancer research is particularly concerning. Too many studies have generated biosignatures using “samples of convenience” that look promising in the lab but fail spectacularly when tested in real patients. Some have even caused harm by misleading treatment decisions.
The solution requires implementing comprehensive health data standardisation practices that ensure data quality from the moment it’s collected through every step of analysis. This isn’t just a technical problem – it’s a cultural shift that requires coordination across entire healthcare systems.
Breaking Down Silos: Integration and Data Sharing
Here’s the thing that drives researchers crazy: we often have all the pieces of the puzzle, but they’re scattered across different institutions, systems, and databases that don’t talk to each other. Data silos are perhaps the biggest barrier to leveraging oncology data analytics effectively.
Legacy systems are a major culprit. Many hospitals and research institutions are running on infrastructure that was cutting-edge in the 1990s but struggles with today’s data volumes and integration requirements. These systems often lack the flexibility needed for modern analytics and cross-institutional collaboration.
Career incentives create another barrier that’s harder to fix with technology. Current academic reward structures often discourage data sharing before publication, creating artificial barriers to collaboration. Researchers worry about being “scooped” by competitors, so they hoard data until they’ve published their findings.
Patient privacy concerns add another layer of complexity. While protecting patient privacy is absolutely crucial, overly restrictive interpretations of privacy regulations can impede legitimate research that could benefit patients. We need frameworks that protect privacy while enabling responsible data sharing.
The path forward involves implementing data analysis in trusted research environments that provide secure, compliant platforms for collaboration. These environments must maintain the highest standards for patient data privacy and security while enabling the kind of large-scale collaboration that modern cancer research demands.
Breaking down these silos isn’t just about better technology – it’s about creating new ways of working together that put patient benefit at the center of everything we do.
The Future is Now: Emerging Technologies and Opportunities
The convergence of artificial intelligence, machine learning, and multiomics integration is creating unprecedented opportunities in oncology data analytics. We’re moving beyond simple data collection toward sophisticated predictive models that can guide treatment decisions in real-time.
The concept of “digital twins” for cancer patients is becoming reality – computer models that capture real-time patient dynamics to create predictive models for treatment decisions. This represents a fundamental shift from reactive to proactive cancer care, where we can anticipate and prevent complications before they occur.
Our AI drug findy platform capabilities are enabling researchers to identify novel therapeutic targets and predict drug responses with unprecedented accuracy, potentially reducing the time and cost of bringing new treatments to patients.
The Power of AI, Machine Learning, and Multiomics
The integration of AI and multiomics is revolutionizing oncology data analytics in several key areas:
AI-Derived Biosignatures: Examples like FOLFOXai for colorectal cancer demonstrate how machine learning can identify patient populations most likely to benefit from specific treatments. However, success requires augmenting genomic-only AI training with emerging molecular profiling datasets including microenvironment, proteome, and epigenome data.
Predictive Oncology: Advanced analytics can now predict treatment responses, toxicities, and long-term outcomes with increasing accuracy. This enables more personalized treatment selection and better patient counseling about expected outcomes.
In Silico Drug Findy: Computational approaches are accelerating the identification of new therapeutic targets and drug combinations. The ATOM Modeling PipeLine (AMPL) exemplifies how AI for target validation in drug findy can advance precision medicine.
Integrated Multiomics: The ability to simultaneously analyze genomic, transcriptomic, proteomic, and clinical data provides unprecedented insights into cancer biology. Advanced analytics with Nextflow pipelines enable researchers to process and integrate these complex datasets efficiently.
The key to success lies in combining these technologies with high-quality, standardized datasets and robust validation frameworks that ensure clinical utility.
Future Trends in Oncology Data Analytics
Several emerging trends are shaping the future of oncology data analytics:
Patient-Centric Systems: The future involves building systems that collect, manage, analyze, and deliver data directly to patients, empowering them to make informed decisions about their care. This represents a fundamental shift from provider-centric to patient-centric healthcare delivery.
Federated Learning: Rather than centralizing all data, federated approaches allow analytics to be performed across distributed datasets while maintaining privacy and security. Our Federated Trusted Research Environment enables secure collaboration across institutions without compromising sensitive patient data.
Real-Time Evidence Generation: Moving beyond traditional clinical trials, we’re developing systems that can generate evidence in real-time from routine clinical care. This creates learning healthcare systems that continuously improve based on every patient interaction.
Longitudinal Data Integration: Future systems will seamlessly integrate data across the entire patient journey, from screening and diagnosis through treatment and survivorship. This longitudinal view enables better understanding of disease progression and treatment effectiveness over time.
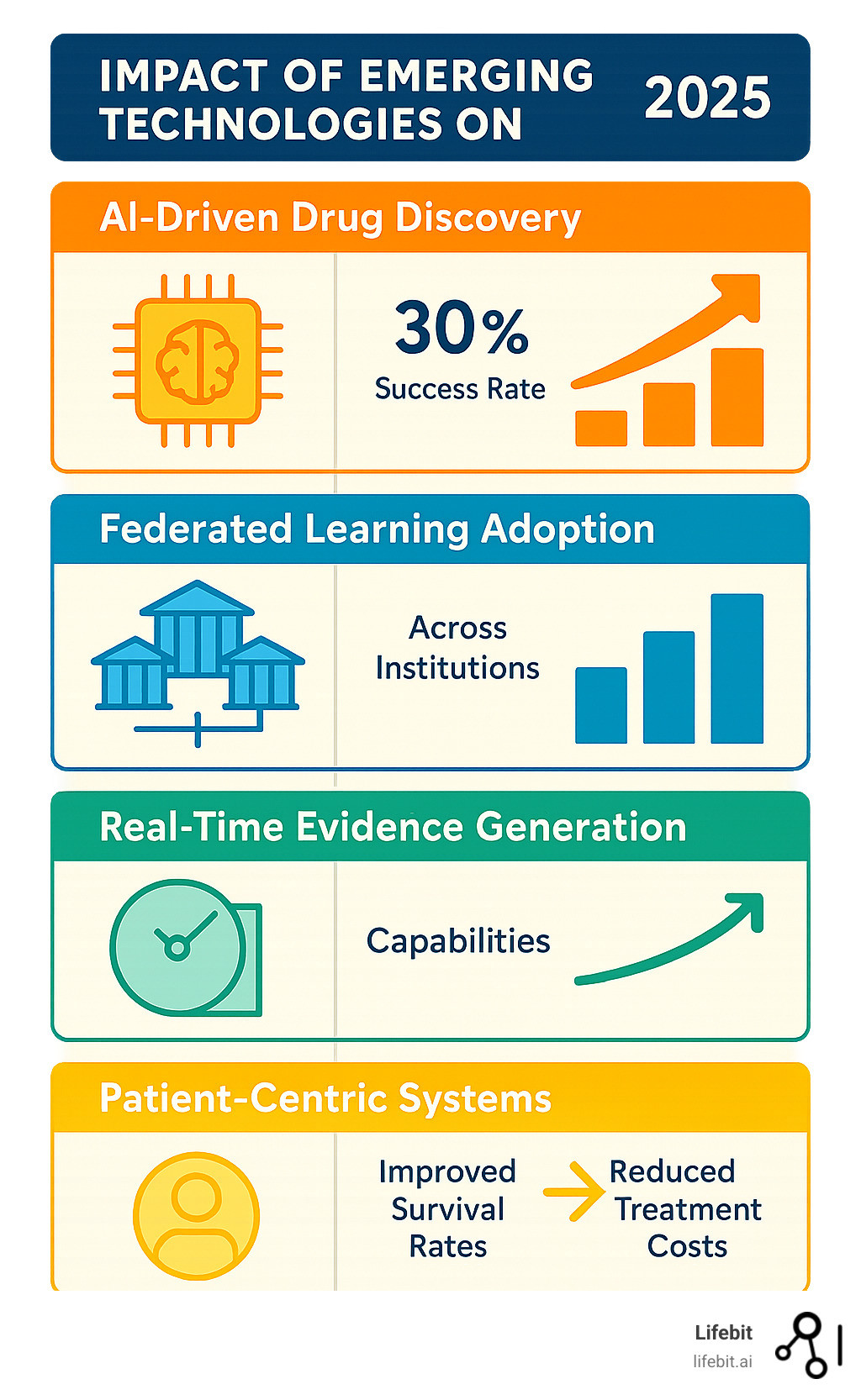
These trends point toward a future where oncology data analytics becomes seamlessly integrated into clinical care, providing real-time insights that improve outcomes for every cancer patient.
Conclusion
We stand at an extraordinary moment in cancer care. The journey from TCGA’s groundbreaking 2.5 petabytes of data to today’s projected zettabytes of genomic information by 2025 represents more than just numbers – it represents hope for millions of cancer patients worldwide.
But let’s be honest about where we are today. Despite all this incredible data, we still have a sobering reality: only 5 % of eligible patients actually benefit from targeted therapies. This gap between what we know and what we can deliver to patients keeps me up at night. It’s exactly why we built Lifebit – to bridge this critical divide between data generation and patient benefit.
The change of cancer care through oncology data analytics isn’t just about having more data. It’s about having the right infrastructure to make that data work for patients. We need to move beyond the current fragmented system where valuable insights remain locked in institutional silos, unable to reach the patients who need them most.
This is where federated approaches become game-changing. Instead of trying to centralise all the world’s cancer data in one place – which raises massive privacy and logistical challenges – we can bring the analytics to the data. Our federated AI platform enables secure, real-time collaboration across global datasets while maintaining the highest standards of patient privacy and regulatory compliance.
The future I envision is one where a cancer patient in rural Montana can benefit from insights generated by combining data from leading cancer centres in Boston, London, and Tokyo. Where an oncologist can access real-time evidence about treatment effectiveness based on thousands of similar cases worldwide. Where pharmaceutical companies can identify promising drug targets by analysing patterns across diverse patient populations.
The convergence of AI, multiomics, and real-world evidence generation is already accelerating the pace of findy. We’re seeing AI-derived biosignatures that can predict treatment responses with unprecedented accuracy. We’re witnessing the emergence of digital twins for cancer patients that can simulate treatment outcomes before a single dose is administered.
But technology alone isn’t enough. We need a fundamental shift in how we approach cancer research and care – from competitive to collaborative, from siloed to integrated, from reactive to predictive. This requires platforms that can support secure collaboration while maintaining the trust and compliance that patients and institutions demand.
At Lifebit, we’re not just building technology – we’re building the foundation for a learning healthcare system where every patient interaction generates insights that can help the next patient. Our Trusted Research Environment, Trusted Data Lakehouse, and R.E.A.L. platform components work together to create an ecosystem where data flows seamlessly from bench to bedside.
The fight against cancer is ultimately a fight for better integration, smarter analytics, and more effective collaboration. Every day we delay in connecting these data dots is another day that patients miss out on potentially life-saving treatments. The tools exist today to transform cancer care – what we need now is the commitment to work together.
Ready to be part of this change? Open up the power of oncology data with Lifebit and help us build a future where every cancer patient receives the most effective, personalised treatment possible. Because in the end, that’s what all this data is really about – giving patients the best possible chance at beating cancer.