
An Essential Guide to Choosing a Secure Research Environment

Updated for 2026
Secure research environments in 2026 have converged on federated TRE architectures. The pattern: data stays at source institutions, compute moves to the data, analytic outputs cross the trust boundary through policy-controlled airlocks. NIST SP 800-53 r5 + NIST SP 800-188 + HIPAA §164.514(b) Expert Determination define the compliance baseline. Production deployments at NIH National Library of Medicine, NHS England, Genomics England, and Singapore MOH show the pattern scales to national-level cohorts.
Why Secure Research Environments Are Essential for Modern Healthcare Research
A secure research environment (SRE) is a protected computing platform that enables researchers to access and analyze sensitive data while maintaining strict security controls and regulatory compliance. Also known as Trusted Research Environments (TREs), these platforms serve as secure digital workspaces where researchers can collaborate on sensitive datasets without compromising data privacy or institutional security.
Key characteristics of secure research environments:
- Controlled access through VPNs, multi-factor authentication, and user verification
- Data protection via encryption, firewalls, and network isolation
- Compliance with regulations like HIPAA, GDPR, and NIST standards
- Audit trails that track all user activities and data movements
- Restricted data egress with approval workflows for research outputs
The need for SREs has never been more critical. As healthcare generates unprecedented volumes of sensitive data – from electronic health records to genomic sequences – traditional research methods fall short. Organizations now handle Protected Health Information (PHI), Personally Identifiable Information (PII), and valuable intellectual property that requires specialized protection.
SREs solve a fundamental challenge: how do you enable groundbreaking research while protecting sensitive data? They create secure digital spaces where researchers can access powerful analytical tools, collaborate across institutions, and generate insights without ever moving raw data outside controlled environments.
As CEO and Co-founder of Lifebit, I’ve spent over 15 years building secure research environments that enable global healthcare breakthroughs through federated data analysis. My experience developing computational biology tools and establishing compliant platforms for pharmaceutical and public sector organizations has shown me how the right secure research environment can transform research capabilities while maintaining the highest security standards.
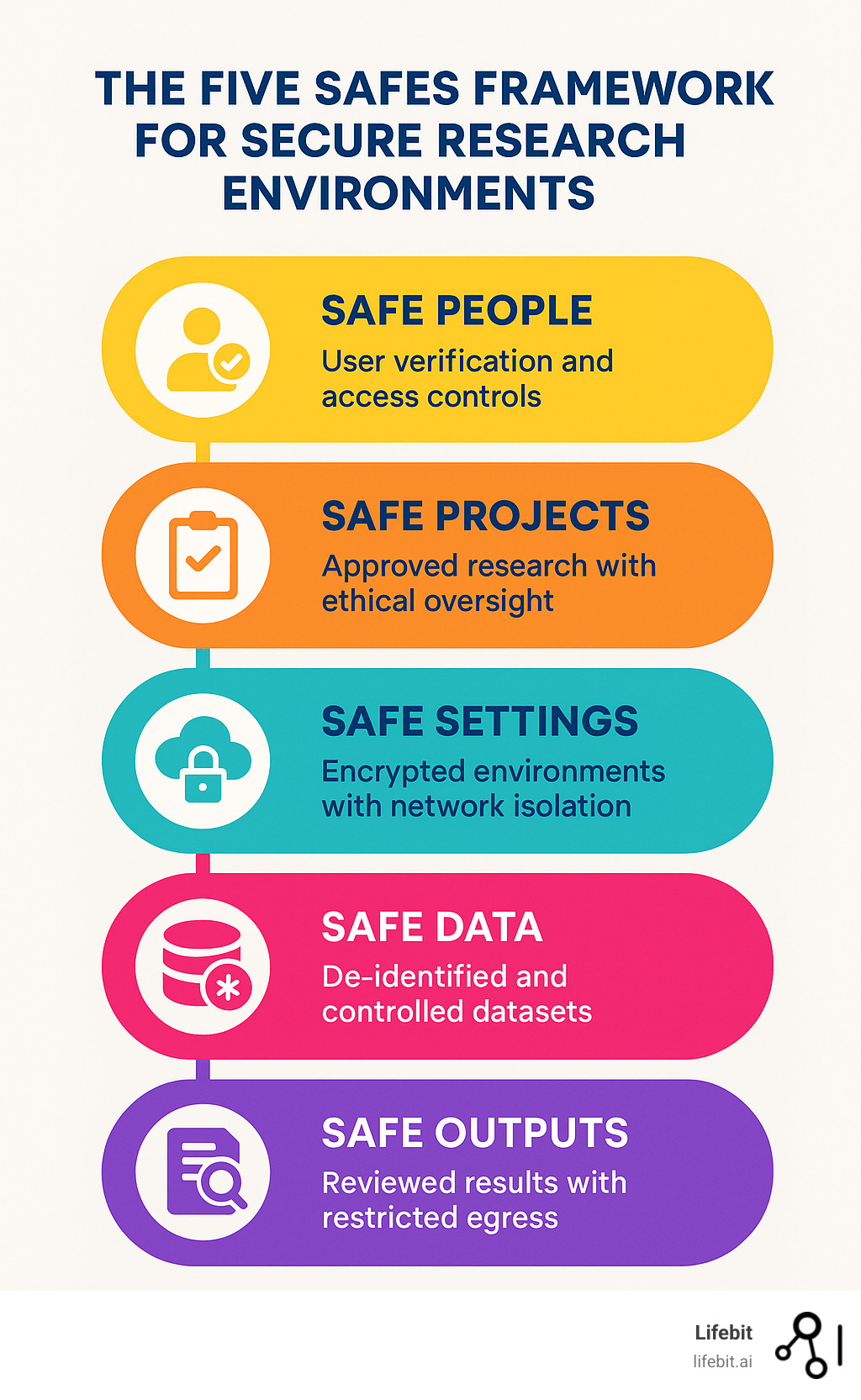
Introduction: What is a Secure Research Environment (SRE) and Why is it Crucial?
The Primary Purpose of an SRE
Think of a secure research environment as a high-tech vault that also happens to be a world-class laboratory. It’s where sensitive data stays locked away from prying eyes, while researchers get all the tools they need to make groundbreaking findies.
The main job of an SRE is pretty straightforward: keep data safe while enabling amazing research. But like most things that sound simple, there’s quite a bit happening behind the scenes.
Data protection sits at the heart of everything. SREs prevent unauthorized access to sensitive information, whether that’s patient health records, genomic data, or proprietary research findings. They’re like having a team of digital bodyguards working around the clock. Modern SREs employ multiple layers of protection including advanced encryption algorithms (AES-256), zero-trust network architectures, and behavioral analytics that can detect unusual access patterns in real-time.
Minimizing institutional risk is another crucial function. Nobody wants to be the organization that accidentally exposed thousands of patient records or lost valuable intellectual property. The financial implications alone are staggering – healthcare data breaches cost an average of $10.93 million per incident according to IBM’s 2023 Cost of a Data Breach Report. Beyond monetary losses, organizations face regulatory penalties, legal liability, and reputational damage that can take decades to repair. SREs help institutions sleep better at night by dramatically reducing the chances of data breaches or compliance violations.
But here’s what makes SREs truly special: they don’t just lock data away – they enable research that wouldn’t be possible otherwise. Researchers get access to powerful analytical tools, high-performance computing resources, and datasets they could never work with on their regular computers. This includes specialized bioinformatics software, machine learning frameworks optimized for healthcare data, and computational resources that can process terabytes of genomic information in hours rather than weeks.
Data stewardship rounds out the core purposes. Data custodians maintain complete control over their valuable datasets while still enabling researchers to extract meaningful insights. This includes granular permission controls, automated data lineage tracking, and the ability to revoke access instantly if needed. It’s like having your cake and eating it too – you keep ownership while maximizing the research value.
Why SREs are Essential in the Age of Big Data
We’re living in a time when biomedical data is growing faster than our ability to securely manage it. And frankly, traditional approaches just can’t keep up anymore.
The volume and complexity of modern research data would have seemed like science fiction just a decade ago. Today’s researchers work with massive genomic datasets containing millions of variants, electronic health records spanning millions of patients across decades, and real-world evidence that contains incredibly sensitive personally identifiable information (PII) and protected health information (PHI). A single whole genome sequence generates approximately 200 gigabytes of raw data, and large-scale studies might involve hundreds of thousands of participants. Your laptop simply wasn’t designed to handle this kind of workload – or keep this kind of data secure.
The complexity extends beyond just size. Modern biomedical research increasingly relies on multi-modal data integration – combining genomics, proteomics, imaging data, clinical records, and patient-reported outcomes. Each data type has its own security requirements, file formats, and analytical needs. Traditional research computing environments struggle to provide the specialized tools and security controls needed for each data modality.
International collaboration has become essential for tackling global health challenges, but it’s also created new headaches. Data sovereignty laws mean you can’t just email a dataset to a colleague in another country. The European Union’s GDPR, the UK’s Data Protection Act, and various national healthcare privacy laws create a complex web of requirements that vary dramatically by jurisdiction. Cyber threats are constantly evolving, and healthcare organizations have become prime targets because patient data is so valuable on the black market – a single medical record can sell for $250-$1,000 compared to just $1-$3 for a credit card number.
As we explored in our data security in nonprofit health research article, these challenges are particularly acute for organizations trying to balance open science with data protection responsibilities.
Regulatory compliance has become a full-time job in itself. HIPAA, GDPR, and other frameworks create complex requirements that can vary dramatically depending on where your data comes from and where your researchers are located. A single misstep can result in millions in fines and damage that takes years to repair. The regulatory landscape is also constantly evolving – new frameworks like the EU’s AI Act and various national AI governance policies are adding additional layers of complexity for research organizations using machine learning and artificial intelligence.
The rise of intellectual property protection concerns adds another layer of complexity. With AI and machine learning becoming central to biomedical research, the algorithms and insights generated from data analysis are often as valuable as the data itself. Organizations need to protect not just the raw data, but also the derived insights, analytical models, and research methodologies that represent years of investment and development.
Secure research environments solve these modern challenges by creating protected digital spaces where researchers can work with sensitive data without the constant worry about security breaches or compliance violations. They provide the computational power needed for modern analytics, the security controls required by regulations, and the collaboration tools necessary for global research initiatives. They’re not just nice to have anymore – they’re essential infrastructure for any serious research organization looking to participate in the data-driven future of biomedical science.
Core Features of a Modern Secure Research Environment

Foundational Security and Technical Features
A secure research environment relies on several mutually reinforcing layers of protection that work together to create an impenetrable digital fortress:
Access controls form the first line of defense. Every user connects through an encrypted VPN tunnel that creates a secure pathway between their device and the research environment. Multi-factor authentication (MFA) goes beyond simple passwords, requiring additional verification through hardware tokens, biometric scans, or time-based codes. Modern SREs implement adaptive authentication that adjusts security requirements based on user behavior, location, and risk factors. Role-based permissions ensure researchers only see the data their project requires, with granular controls that can restrict access down to individual data fields or patient cohorts.
Encryption everywhere means data is protected whether it’s moving between systems or sitting in storage. Data in transit is protected using TLS 1.3 or higher encryption protocols, while data at rest uses AES-256 encryption with hardware security modules (HSMs) managing encryption keys. Network segmentation creates isolated zones within the environment, preventing lateral movement if one area is compromised. Advanced firewalls use deep packet inspection and behavioral analysis to identify and block suspicious traffic patterns.
Immutable storage and audit trails provide both security and scientific integrity. Once data is written to immutable storage systems, it cannot be silently changed or deleted, ensuring data integrity throughout the research lifecycle. Comprehensive audit trails capture who did what, when, and from where – critical for both security investigations and research reproducibility. These logs are tamper-proof and stored separately from the main research environment to prevent unauthorized modification.
Continuous monitoring employs artificial intelligence and machine learning to detect anomalous behavior in real-time. Advanced User and Entity Behavior Analytics (UEBA) systems learn normal patterns of user activity and raise alerts when someone accesses unusual data, works at odd hours, or exhibits other potentially suspicious behaviors. Security Information and Event Management (SIEM) systems correlate events across the entire environment to identify complex attack patterns that might be missed by individual security tools.
As we explained in Unwrapping Lifebit data security, this “defence-in-depth” model protects against both external attackers and insider mistakes.
Meeting Critical Compliance and Regulatory Standards
Modern SREs arrive pre-configured to satisfy a comprehensive array of regulations including HIPAA (Health Insurance Portability and Accountability Act), GDPR (General Data Protection Regulation), NIST SP 800-171/53 (National Institute of Standards and Technology frameworks), CMMC (Cybersecurity Maturity Model Certification), and GxP (Good Practice guidelines for pharmaceutical research).
The complexity of maintaining compliance across multiple frameworks simultaneously cannot be overstated. Each regulation has specific technical requirements, documentation standards, and audit procedures. For example, HIPAA requires specific safeguards for PHI, detailed risk assessments, and breach notification procedures. GDPR adds requirements for data subject rights, privacy by design, and cross-border data transfer restrictions. NIST frameworks provide detailed security controls that must be implemented, monitored, and regularly assessed.
Pre-approved System Security Plans (SSPs) and Authority to Operate (ATO) documentation can be attached to grant applications, eliminating weeks of paperwork and accelerating project timelines. These documents provide detailed descriptions of security controls, risk assessments, and compliance procedures that satisfy regulatory requirements. See our ISO certification for genomic data security for a practical example of how comprehensive certification processes work.
Scalable Compute and Analytical Tooling
Research only thrives when security meets performance. SREs therefore pair strong controls with elastic resources that can scale from small pilot studies to massive population-level analyses:
HPC & GPU options provide computational power that would be impossible for most organizations to maintain in-house. Researchers can spin up anything from a small 2-core virtual machine for basic statistical analysis to a 64-core, GPU-accelerated powerhouse capable of training complex deep learning models within minutes. Modern SREs offer specialized hardware including Tensor Processing Units (TPUs) for AI workloads, Field-Programmable Gate Arrays (FPGAs) for custom computational tasks, and high-memory instances capable of loading entire genomic datasets into RAM for ultra-fast processing.
Pre-installed toolkits eliminate the time-consuming process of software installation and configuration. Popular tools like R, Python, SAS, STATA, Jupyter notebooks, and specialized bioinformatics packages are ready out-of-the-box with all necessary dependencies and security configurations. Bring-Your-Own-Software (BYOS) capabilities support specialized pipelines and proprietary tools through containerized deployment systems that maintain security while enabling customization.
Containerized workflows using technologies like Docker and Kubernetes guarantee reproducibility across different computing environments and simplify collaboration across teams and institutions. Researchers can package their entire analytical pipeline – including code, dependencies, and configuration – into portable containers that run identically regardless of the underlying infrastructure. This approach also improves security by isolating different analytical processes and preventing conflicts between software packages.
Data integration and harmonization tools address one of the biggest challenges in multi-institutional research: making datasets from different sources work together. Modern SREs include automated tools for data standardization, quality assessment, and harmonization that can transform disparate datasets into analysis-ready formats while maintaining full audit trails of all changes.
Our post on the key features of a federated data lakehouse dives deeper into how these capabilities integrate with federated governance frameworks.
The result is a “supercomputer wrapped in Fort Knox”: researchers get the computational speed and analytical power they need to tackle the most complex biomedical questions, while data stewards maintain the control and security they demand to protect sensitive information.
Choosing the Right SRE Model for Your Needs
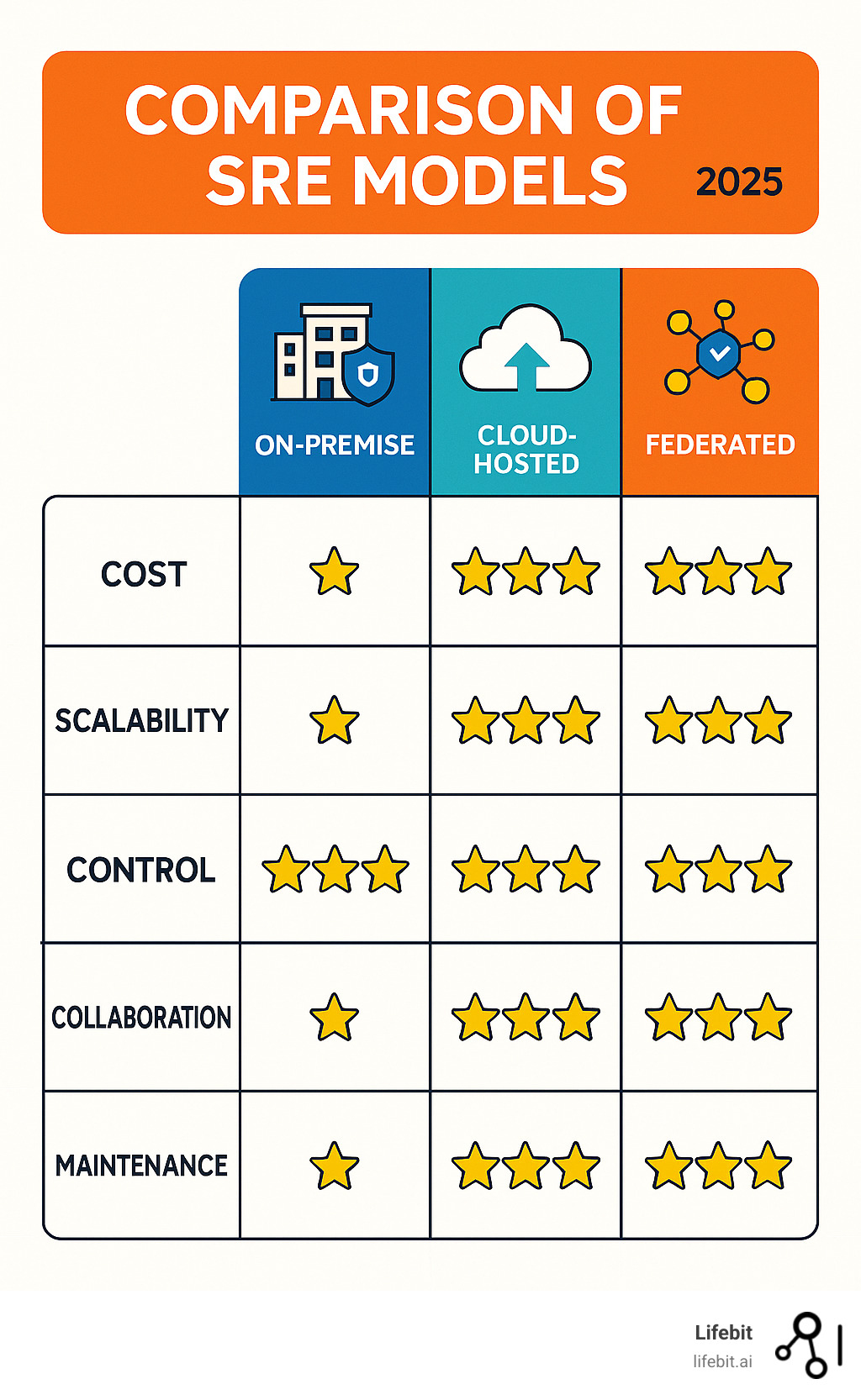
Selecting the right secure research environment model is like choosing the perfect workspace for your research team. Each approach has its own personality, strengths, and quirks. Understanding these differences will help you make the best decision for your organization’s unique needs and budget.
The three main models—on-premise, cloud-hosted, and federated—each solve different challenges. Your choice depends on factors like cost considerations, scalability requirements, control preferences, and collaboration needs. Let’s explore what makes each model tick.
On-Premise vs. Cloud-Based SREs
On-premise SREs are like having your own private research laboratory. You build and maintain everything in your institutional data centers, giving you complete control over every aspect of your environment. This approach offers excellent physical security since your data never leaves your building, and you can customize every detail to match your specific requirements.
However, this control comes with significant capital expenditure (CapEx) costs. You’ll need to invest in servers, storage, networking equipment, and ongoing maintenance overhead. Think of it as buying a house—you own everything, but you’re also responsible for every repair and upgrade.
Cloud-based SREs flip this model entirely. Instead of owning the infrastructure, you rent it as an operational expenditure (OpEx). This approach offers incredible scalability—need more computing power for a large analysis? You can scale up instantly. Working with a distributed team? Remote access is built right in.
The cloud model eliminates much of the technical burden from your team. No more worrying about server maintenance, security patches, or hardware failures. The cloud provider handles these details, letting your researchers focus on what they do best—research.
The Rise of Federated Trusted Research Environments
Here’s where things get really exciting. Federated Trusted Research Environments represent a breakthrough in how we think about secure data collaboration. Instead of moving data to where the analysis happens, federated systems bring the analysis to where the data lives.
This approach solves one of the biggest headaches in modern research: data sovereignty issues. Imagine trying to combine patient data from hospitals across different countries, each with their own privacy laws and regulations. Traditional approaches would require copying data to a central location, creating legal nightmares and security risks.
With federated systems, data stays local under the control of its original custodians. Our federated data analysis capabilities enable researchers to run analyses across multiple datasets simultaneously without ever moving the raw data.
This approach is particularly powerful for cross-institutional collaboration and multi-omic data analysis. Researchers can access insights from vast, distributed datasets while maintaining the highest security standards. It’s like having a secure research network that spans the globe.
The potential for global precision medicine becomes real when you can analyze data from thousands of institutions without compromising patient privacy. Our federated trusted research environment platform demonstrates how this vision is becoming reality.
Projects like building European trusted research environments show how entire regions are embracing federated approaches to enable breakthrough research while respecting local data protection laws.
The federated model represents the future of collaborative research—secure, compliant, and globally scalable. It’s not just about technology; it’s about creating a new paradigm where sensitive data can contribute to scientific progress without ever leaving its secure home.
Access, Operations, and Support: The Researcher’s Experience

Who Uses a Secure Research Environment and for What?
The diversity of users and applications in modern SREs reflects the broad impact these platforms have across the biomedical research ecosystem:
Academic research teams represent the largest user group, spanning multiple disciplines and research areas. Population health researchers use SREs to analyze large-scale epidemiological datasets, tracking disease patterns across diverse populations while maintaining individual privacy. Genomics researchers process massive sequencing datasets to identify disease-associated variants, develop polygenic risk scores, and understand the genetic basis of complex diseases. Clinical researchers conduct retrospective analyses of electronic health records, prospective cohort studies, and real-world evidence studies that inform clinical practice guidelines.
Biopharma scientists leverage SREs throughout the drug development lifecycle. During drug findy, researchers analyze multi-omic datasets to identify novel therapeutic targets and biomarkers. Clinical development teams use SREs to analyze clinical trial data, conduct safety analyses, and develop companion diagnostics. Post-market surveillance activities including pharmacovigilance rely on SREs to analyze real-world safety data from multiple sources while maintaining patient privacy.
Government and public health agencies use SREs for critical public health functions. Disease surveillance systems monitor infectious disease outbreaks, track antimicrobial resistance patterns, and identify emerging health threats. Policy planning activities use SREs to analyze population health data and model the impact of different intervention strategies. Crisis response capabilities became particularly important during the COVID-19 pandemic, when public health agencies needed to rapidly analyze genomic surveillance data, track variant emergence, and coordinate response efforts across multiple jurisdictions.
Regulatory agencies increasingly rely on SREs to review submissions from pharmaceutical companies, conduct independent analyses of clinical trial data, and monitor post-market safety signals. The FDA’s Sentinel System, for example, uses secure distributed data networks to monitor the safety of medical products across multiple healthcare systems.
The Genomics England research environment demonstrates how these diverse user groups can collaborate effectively while maintaining strict data protection standards.
The User Journey: From Request to Results
The user experience in a modern SRE is designed to balance security requirements with research efficiency:
1. Access request and approval process begins with researchers submitting a comprehensive project proposal that includes research objectives, methodology, ethical approvals, and data use agreements. The review process typically involves multiple stakeholders including data stewards, ethics committees, and security teams. Advanced SREs use automated workflows to streamline this process, with AI-powered tools that can flag potential issues and route applications to appropriate reviewers. The approval process typically takes 2-4 weeks for standard projects, though expedited review is available for time-sensitive research.
2. Onboarding and training ensures users understand both the technical capabilities and security requirements of the environment. This includes comprehensive security awareness training covering topics like password management, phishing recognition, and incident reporting procedures. Technical training covers platform navigation, data access procedures, and analytical tool usage. Many SREs offer role-specific training programs custom to different user types – basic training for occasional users, advanced training for power users, and specialized training for data stewards and administrators.
3. Data ingress and validation involves multiple automated and manual checks to ensure data quality and security. Approved datasets arrive through encrypted channels using secure file transfer protocols or dedicated network connections. Automated validation processes check file integrity, scan for malware, and verify data formats. Data profiling tools analyze incoming datasets to identify potential quality issues, privacy risks, and integration challenges. Automated de-identification processes remove or mask direct identifiers while preserving analytical utility.
4. Analysis and collaboration takes place within isolated virtual desktops or containerized environments that provide researchers with familiar tools while maintaining security. Modern SREs support real-time collaboration through shared workspaces, version control systems, and integrated communication tools. Computational notebooks allow researchers to document their analytical processes, share code, and ensure reproducibility. Full activity logging runs continuously in the background, capturing all user actions, data access patterns, and computational processes for audit and reproducibility purposes.
5. Results review and egress involves careful scrutiny of all outputs before they leave the secure environment. Statistical disclosure control procedures ensure that aggregated results cannot be used to identify individual participants. Automated screening tools flag potentially sensitive outputs for manual review. Data stewards review all egress requests to ensure compliance with data use agreements and regulatory requirements. Only aggregated, de-identified, or explicitly approved outputs are permitted to leave the SRE.
Lifebit Data Bridge automates many of these steps, using intelligent workflows and AI-powered tools to ensure security never becomes a bottleneck to legitimate research activities.
Support and Training Infrastructure
Effective support systems are crucial for SRE success, requiring specialized expertise that goes far beyond traditional IT support:
Specialized help desk services are staffed by experts who understand both the technical complexities of secure research environments and the unique needs of biomedical researchers. Support staff typically include bioinformaticians, data scientists, security specialists, and regulatory compliance experts. Tiered support models ensure that simple questions are resolved quickly while complex issues receive appropriate expert attention. 24/7 availability is often provided for critical research activities and security incidents.
Comprehensive documentation and training materials include step-by-step guides covering everything from initial login procedures to advanced analytical techniques. Interactive tutorials help new users steer the platform efficiently. Best practice guides share lessons learned from successful research projects and help users avoid common pitfalls. Video training libraries provide visual demonstrations of complex procedures. Community forums enable users to share experiences and learn from each other while maintaining appropriate security boundaries.
Regular security briefings and updates keep users informed about evolving threats, policy changes, and new security features. Phishing simulation exercises help users recognize and respond appropriately to social engineering attacks. Incident response training ensures users know how to report security concerns and respond to potential breaches. Compliance updates keep users informed about changing regulatory requirements and their implications for research activities.
For organizations committed to transparency and continuous improvement, vulnerability reporting processes like our public page Report a security vulnerability demonstrate accountability and encourage responsible disclosure of potential security issues.
The Broader Impact: Benefits and Upholding Research Integrity
Key Benefits of a Secure Research Environment
Researchers
- Access to sensitive, otherwise unreachable datasets
- HPC power without infrastructure headaches
- Built-in compliance so they can focus on science
Institutions
- Dramatically reduced breach and penalty risk
- Proof of compliance boosts reputation and attracts talent
Data Stewards
- Fine-grained control and complete audit trails
- Assurance that participant privacy remains intact
See more in our posts on the advantages of trusted research environments and preserving patient data privacy.
Fostering Research Integrity and Security
The G7 Best Practices state that “openness and security are complementary.” SREs demonstrate this by combining:
- Transparency – Every action is logged and auditable.
- Due diligence – Rigorous vetting of people and projects.
- Risk mitigation – Proactive monitoring and rapid incident response.
- Ethical oversight – Seamless ties to institutional review boards.
Frameworks such as the UK Trusted Research initiative and the US DoD guidance on unwanted foreign influence provide clear blueprints. Our own piece on transparency and data sharing in science explores how SREs operationalise these principles.
Frequently Asked Questions about Secure Research Environments
What is the difference between an SRE and a TRE?
Different acronyms, same concept: a secure, compliant workspace for sensitive data. Whether it is called Secure Research Environment (SRE), Trusted Research Environment (TRE), Secure Data Environment (SDE), or Data Clean Room, the core capabilities are identical – strong access controls, encryption, auditability, and governance.
Can I bring my own data into an SRE?
Yes, provided it passes a brief security and ethics review. After steward approval, your dataset is transferred through encrypted channels, validated, and sandboxed so it can safely sit alongside existing data. Our guide on creating research-ready health data explains how to prepare files for smooth import.
How much does an SRE cost?
Costs scale with compute needs:
- Standard setups – roughly $12–25 per active user day.
- HPC or GPU nodes – $65–275 per day, depending on core/GPU count.
- Enterprise licences – custom monthly pricing that bundles users, storage, and support.
These fees include security, compliance, and specialist support that would be far more expensive to build in-house.
Conclusion: The Future of Collaborative and Secure Research
The world of biomedical research is changing fast, and secure research environments are no longer a luxury – they’re becoming as essential as laboratories themselves. Think about it: we’re dealing with global health challenges that don’t respect borders, yet our most valuable research data often can’t cross them due to privacy and security concerns.
This is where the future gets exciting. We’re moving toward a world where researchers can collaborate across continents without ever moving sensitive data from its home. Federated approaches are making this possible, allowing computation to travel to the data rather than the other way around. It’s like having a universal translator for research – enabling global conversations while respecting local privacy laws.
AI-driven insights are already changing how we analyze complex biomedical data. Imagine real-time analytics that can spot drug safety signals across multiple countries simultaneously, or machine learning models that can identify new therapeutic targets by analyzing genomic data from diverse populations. These aren’t distant possibilities – they’re happening now in secure research environments around the world.
The beauty of modern platforms lies in their ability to handle secure multi-party computation. This means researchers can collaborate on sensitive datasets without anyone having to compromise their data governance policies. It’s collaborative science at its finest, with security built in from the ground up.
For organizations looking to be part of this research revolution, choosing the right platform is crucial. Our Lifebit Trusted Research Environment exemplifies this next-generation approach, offering secure, real-time access to global biomedical data with built-in capabilities for harmonization, advanced AI/ML analytics, and federated governance.
The decision you make about your secure research environment today will shape your organization’s research capabilities for years to come. It’s not just about meeting current compliance requirements – it’s about positioning yourself to participate in the collaborative, AI-powered research ecosystem that’s emerging.
As we continue pushing the boundaries of what’s possible in biomedical research, these secure platforms serve as the bridge between groundbreaking findy and responsible data stewardship. They ensure that while we’re reaching for scientific breakthroughs, we never lose sight of protecting the privacy and security of the individuals whose data makes those findies possible.
The future of research is federated, secure, and collaborative. And it’s already here.
2 thoughts on “An Essential Guide to Choosing a Secure Research Environment”
Comments are closed.